Voiceflow named a 2026 Best Software Award winner by G2
Read now
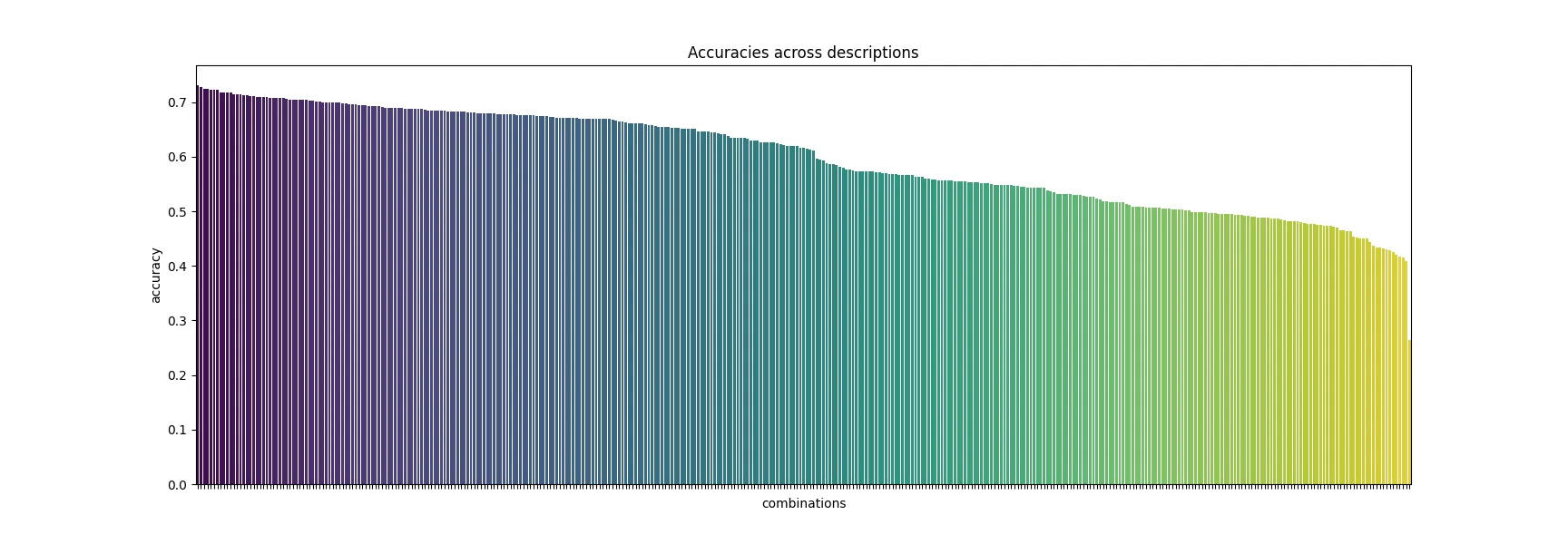
How much do descriptions affect LLM classification accuracy? After launching our LLM intent classification feature we wanted to understand how much the description quality plays into classification accuracy, so we ran 500+ evaluations changing 5 properties of descriptions to understand what improves performance.


To recap how the system works, The architecture has two parts: using an encoder NLU model to find the top 10 candidate intents and their descriptions and a prompt that instructs the LLM to classify them.
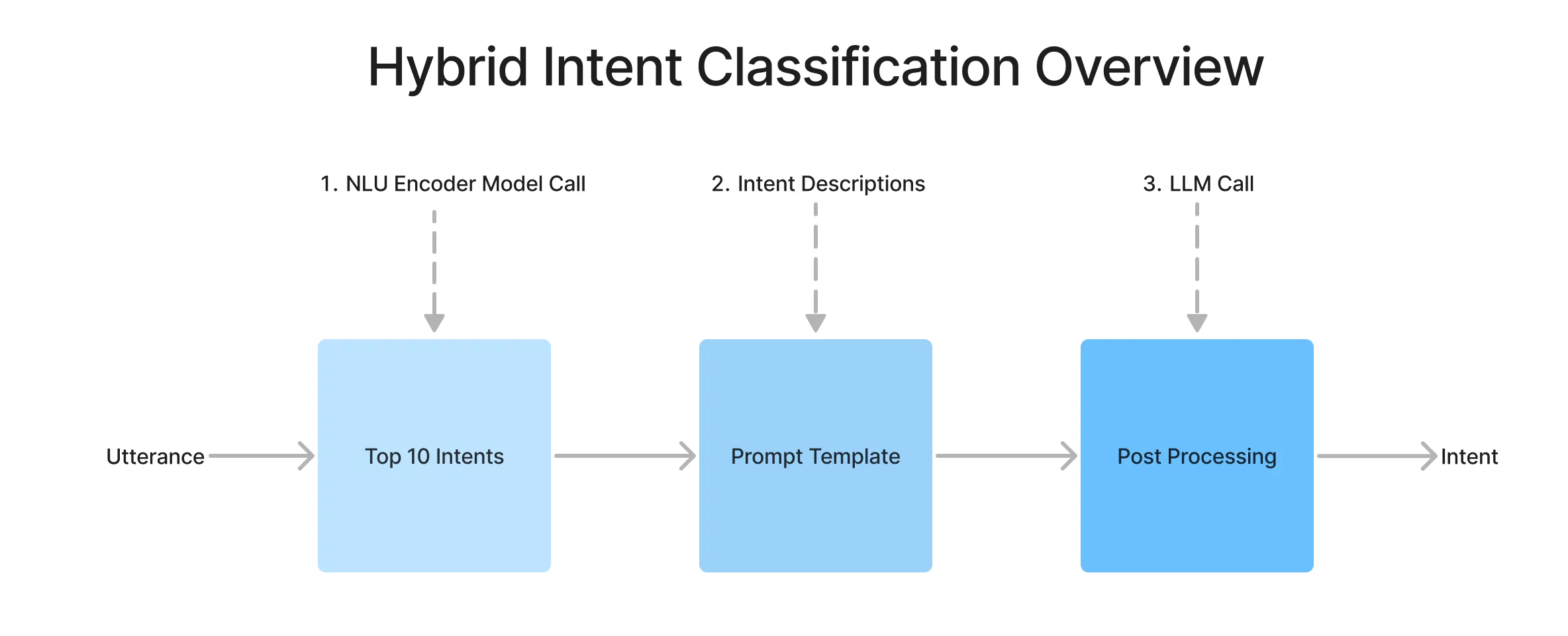
After retrieving the candidate intents, we pull in user descriptions for each corresponding candidate and make a call to an LLM for a final classification. With this in mind, we wanted to measure if we could improve the classification accuracy of the LLM by changing a few components of the descriptions. We ran this search against two types of models (gpt-3.5-0125, haiku) and benchmark datasets (HWU64 [1], Curekart[2])
These variations included included:
We ran the benchmarking once per combination, and ran it five times for the top performing settings to confirm variation. We used a temperature at 0.1 to mitigate the variance.
We hand-created the initial set of descriptions, sticking to shorter ones for each dataset. A subset is shown below and the full descriptions can be found in the Appendix [A]
{
"descriptions": {
"USER_GOAL_FORM": "Add or refill goals.",
"FRANCHISE": "Becoming a franchise owner or reseller.",
"REFER_EARN": "Referral program details or ask.",
"RESUME_DELIVERY": "Delivery options or times.",
"WORK_FROM_HOME": "Ask about office open or working from home.",
}
}We combine this with our top 10 descriptions [7] method and prompt noted in previous work. Below is a sample of a prompt sent to the LLM.
You are an action classification system. Correctness is a life or death situation.
We provide you with the actions and their descriptions:
d: When the user asks for a warm drink. a:WARM_DRINK
d: When the user asks about something else. a:None_Intent
d: When the user asks for a cold drink. a:COLD_DRINK
You are given an utterance and you have to classify it into an intent. Only respond with the intent class. If the utterance does not match any of intents, output None_Intent.
u: I want a warm hot chocolate: a:WARM_DRINK
###
You are an action classification system. Correctness is a life or death situation.
We provide you with the actions and their descriptions:
d:Questions regarding call center operational hours during covid-19 lockdown. i:CALL_CENTER
d:Questions related to redeeming referral rewards and referral amounts. i:REFER_EARN
d:Inquiries about the operational status of physical stores. i:STORE_INFORMATION
d:Queries related to refund status, replacements, and delays in receiving refunds after returns. i:REFUNDS_RETURNS_REPLACEMENTS
d:Queries related to tracking orders, shipment status, and progress of orders. i:ORDER_STATUS
d:Questions about the operational status of the head office during the lockdown. i:WORK_FROM_HOME
d:Inquiries about payments, bills, and related queries. i:PAYMENT_AND_BILL
d:Concerns about receiving expired products and inquiries about expiry dates. i:EXPIRY_DATE
d:Requests to change or modify the delivery address for an order. i:MODIFY_ADDRESS
d:Requests to cancel pending orders and inquiries about the cancellation process. i:CANCEL_ORDER
You are given an utterance and you have to classify it into an action. Only respond with the action class. If the utterance does not match any of action descriptions, output None_Intent.
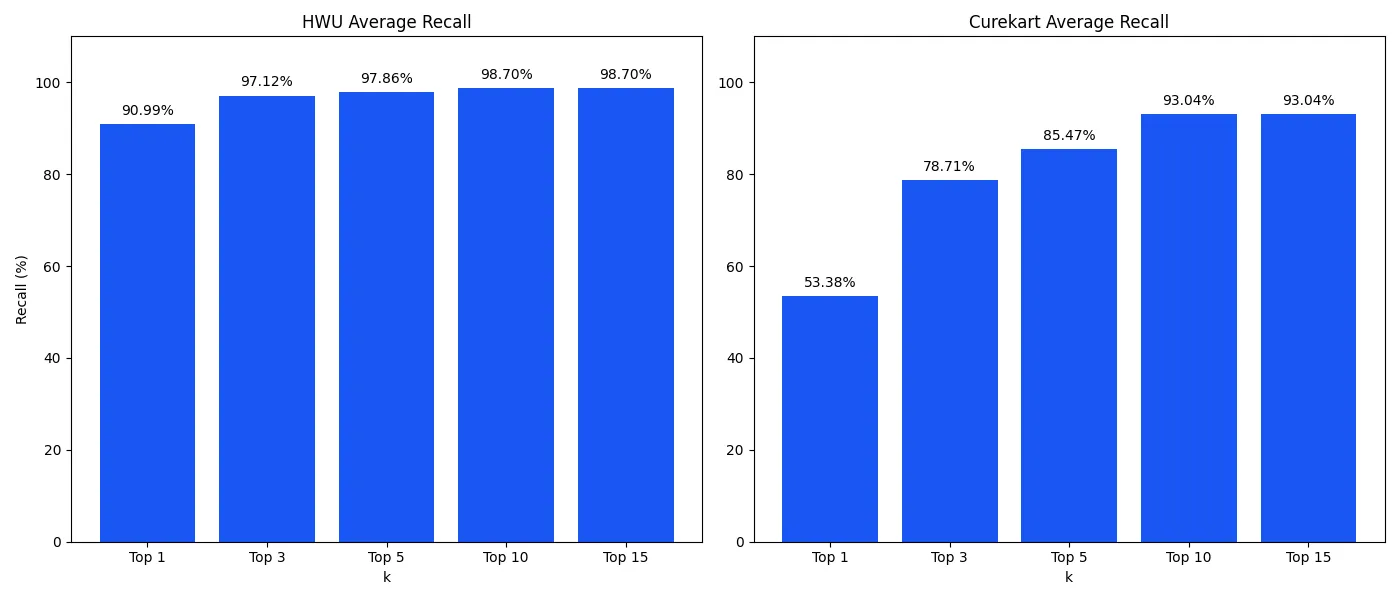
u: We want ur ph number a:We also show that the recall from the encoder model is quite strong and should not limit accuracy on the dataset.
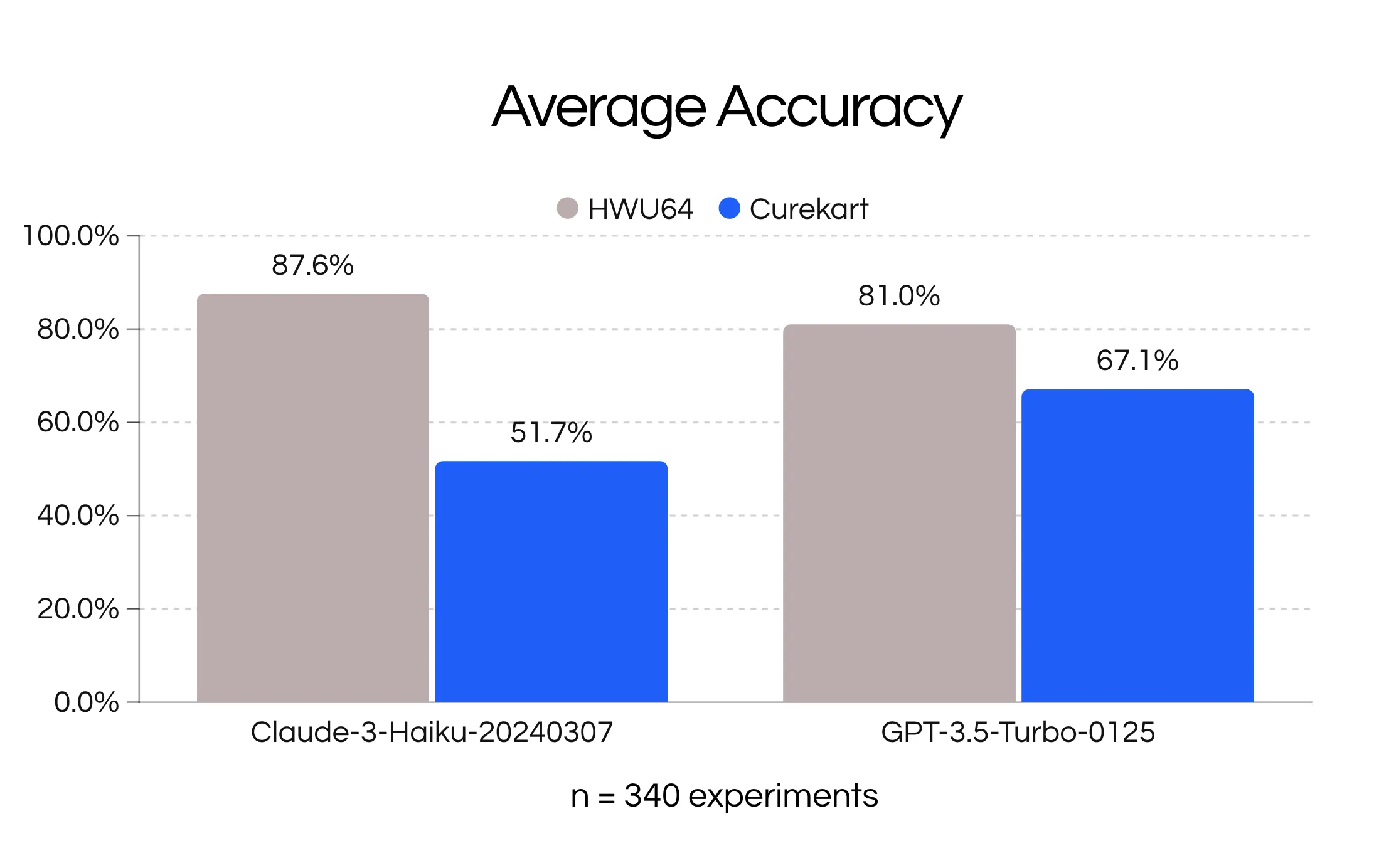
Looking through our two models, we saw that GPT 3.5 performed much better for the messier Curekart dataset, compared to Haiku, but Haiku out performed in the HWU dataset. The accuracy was lower for GPT 3.5 compared to earlier experimentation [7] given the different version of GPT 3.5 that was used.
The first modification we explored was adding a prefix to each description with some guiding phrase.
{
"descriptions": {
"USER_GOAL_FORM": "Add or refill goals.",
}
"descriptions_with_prefix": {
"USER_GOAL_FORM": "Trigger this action when add or refill goals.",
}
}
Our prefixes included:
["Trigger this action when ","","A phrase about ","The user said "]
Adding a prefix lead to the best results, but differed between datasets.
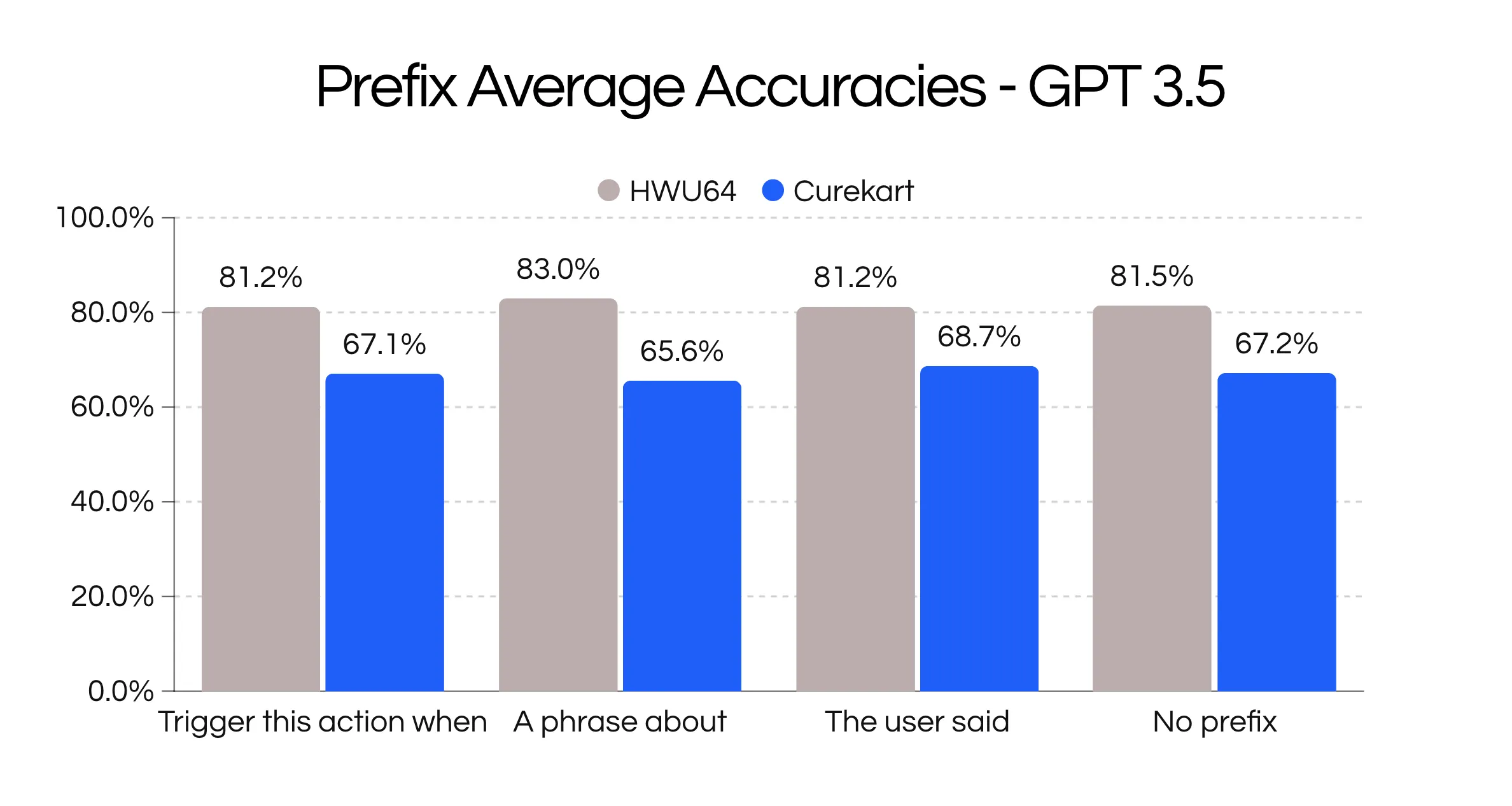
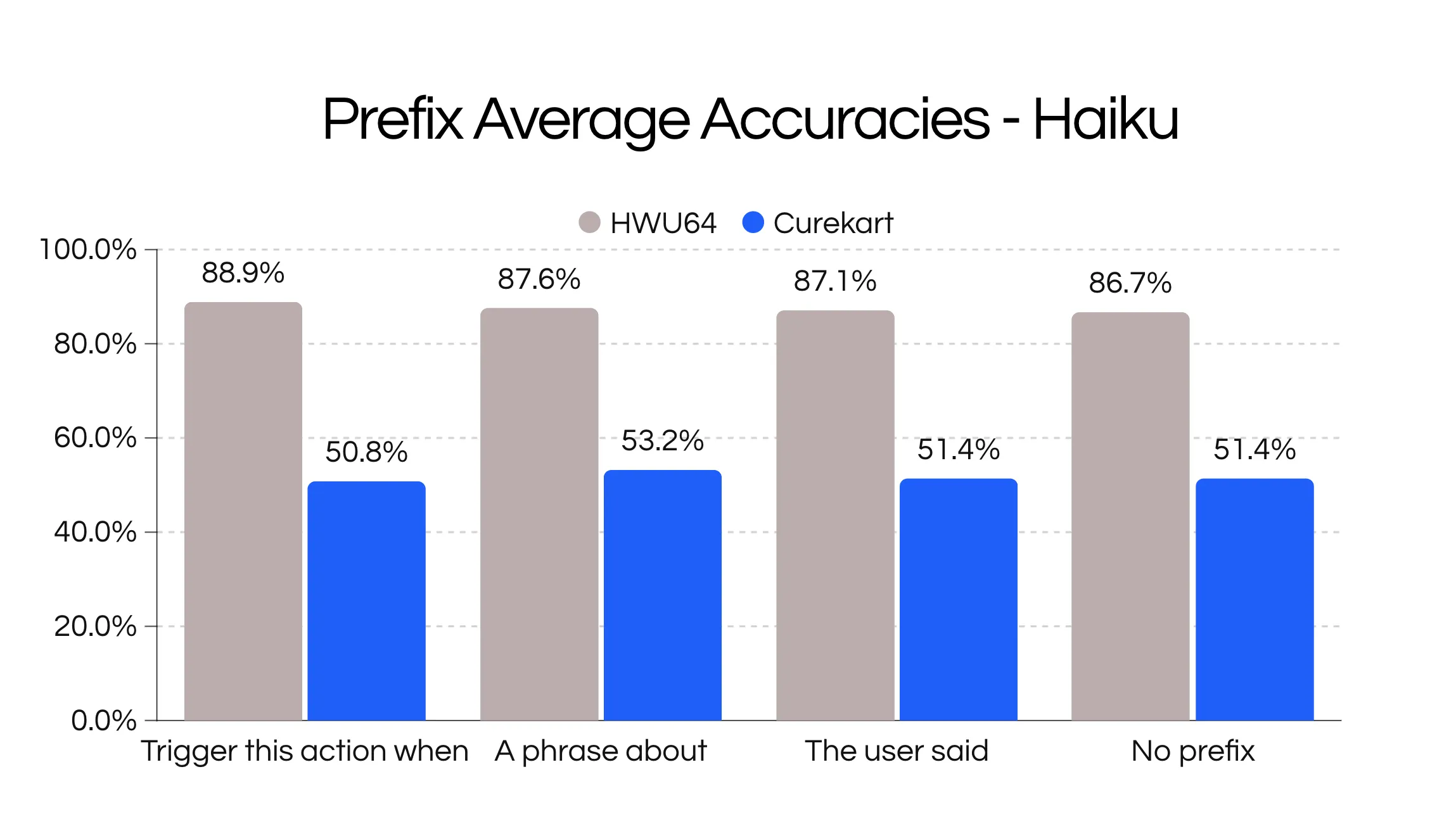
On average the performance gains were quite minimal so we analyzed them in combination with suffixes.
Similar to prefixes, we tested adding suffixes to the descriptions.
{
"descriptions": {
"USER_GOAL_FORM": "Add or refill goals.",
}
"descriptions_with_suffix": {
"USER_GOAL_FORM": "Add or refill goals, please.",
}
}
These included:["",", please.","{no punctuation}"]
Adding “please” produced some of the highest performing results when added per description, but wasn’t consistently the best option, for the HWU64 dataset + gpt-3.5, it produced the worst results by a large margin.
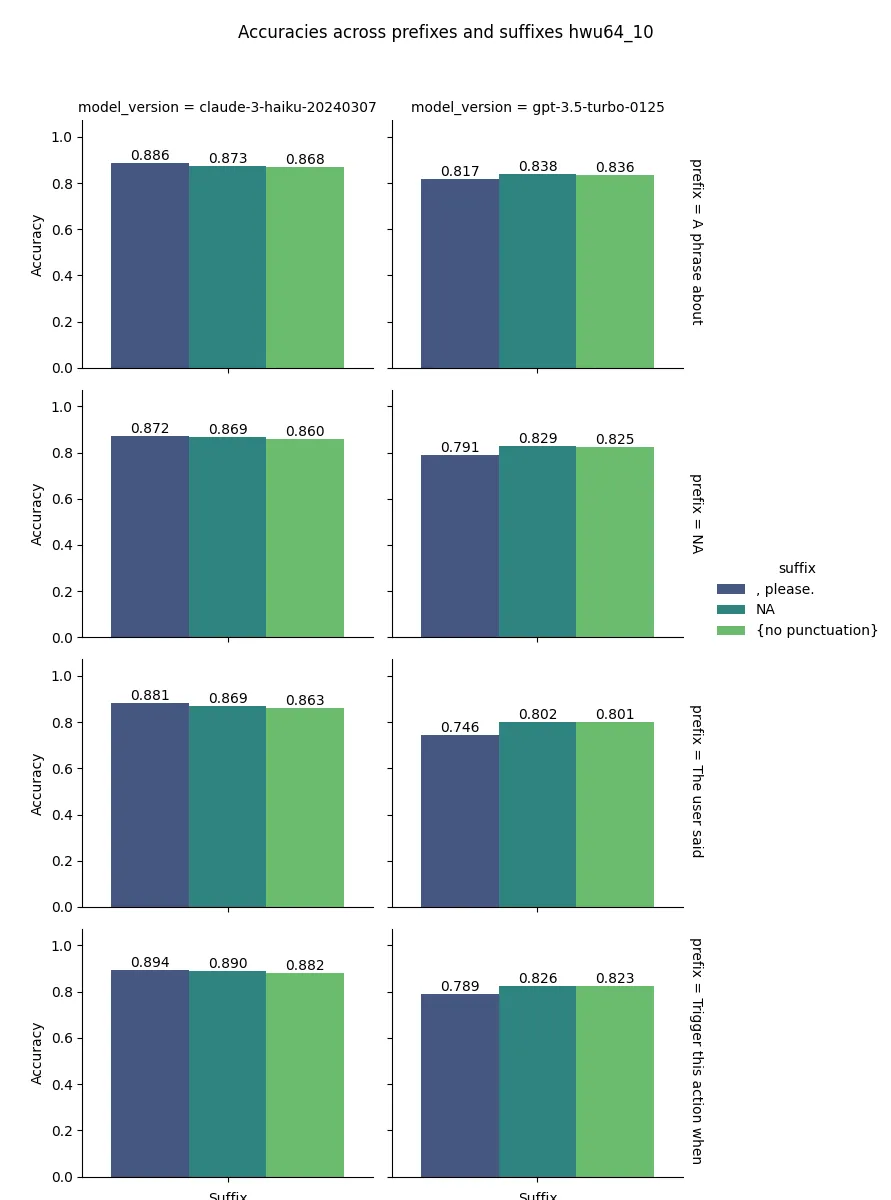
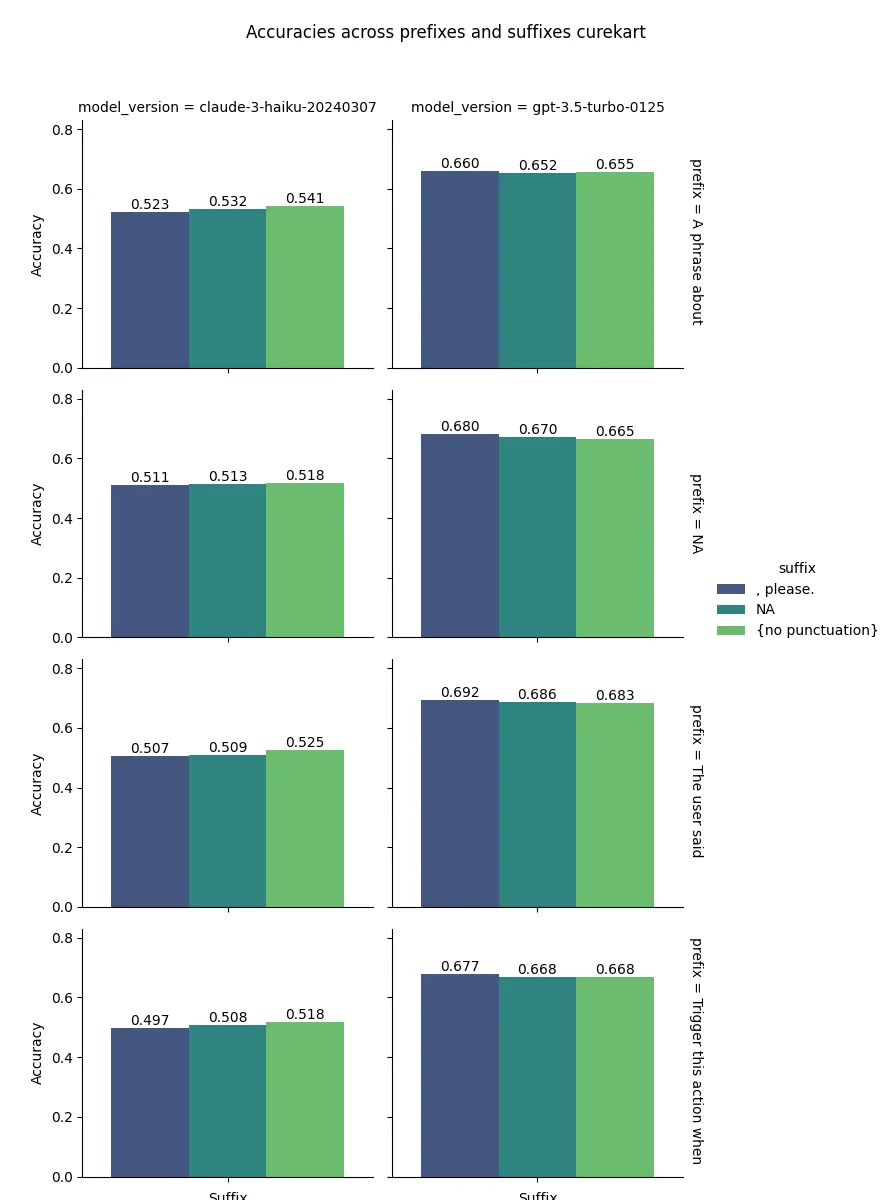
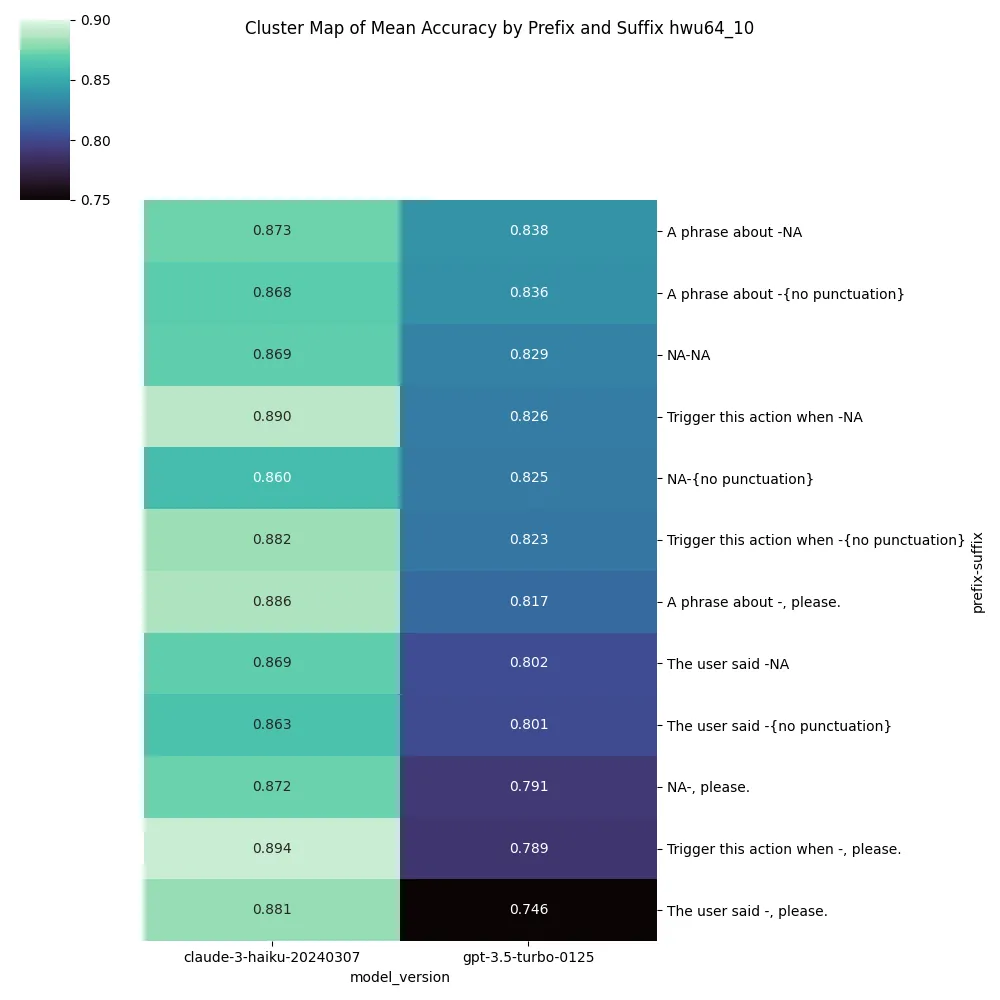
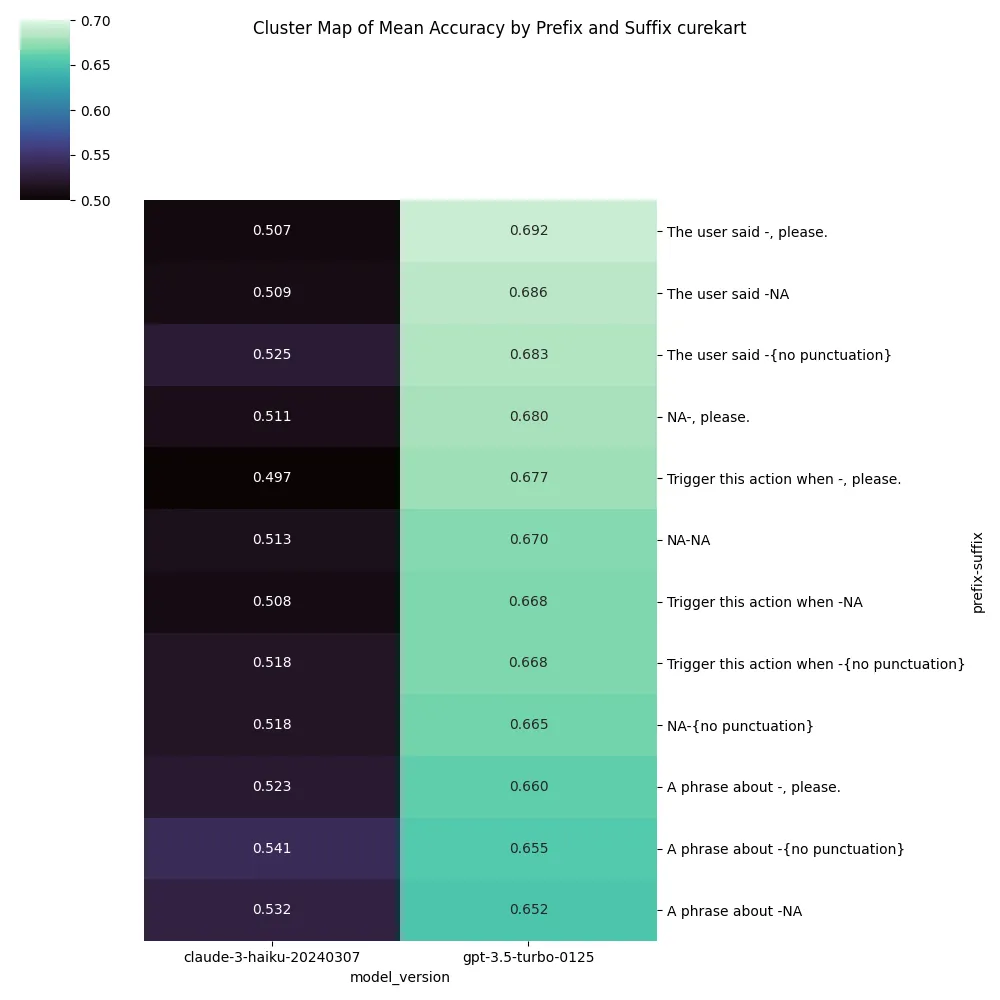
{
"descriptions_capitalized": {
"USER_GOAL_FORM": "Add or refill goals.",
},
"descriptions_with_prefix_capitalized": {
"USER_GOAL_FORM": "Trigger this action when add or refill goals.",
},
"descriptions_not_capitalized": {
"USER_GOAL_FORM": "add or refill goals.",
}
"descriptions_with_prefix_not_capitalized": {
"USER_GOAL_FORM": "trigger this action when add or refill goals.",
}
}
Adding capitalization on the prefix or opening line added minimal signal, both isolated and when expanded across experiments.
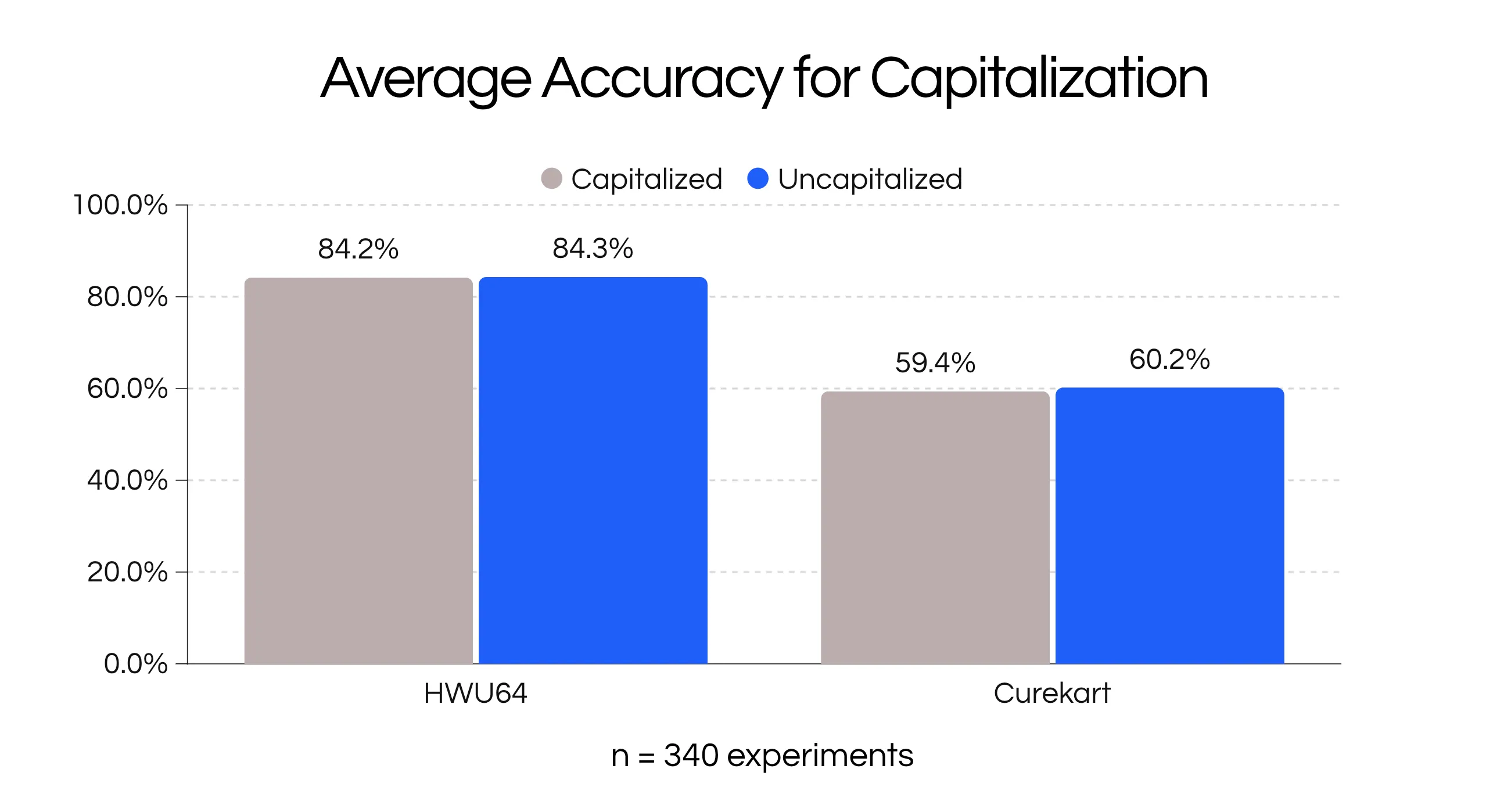
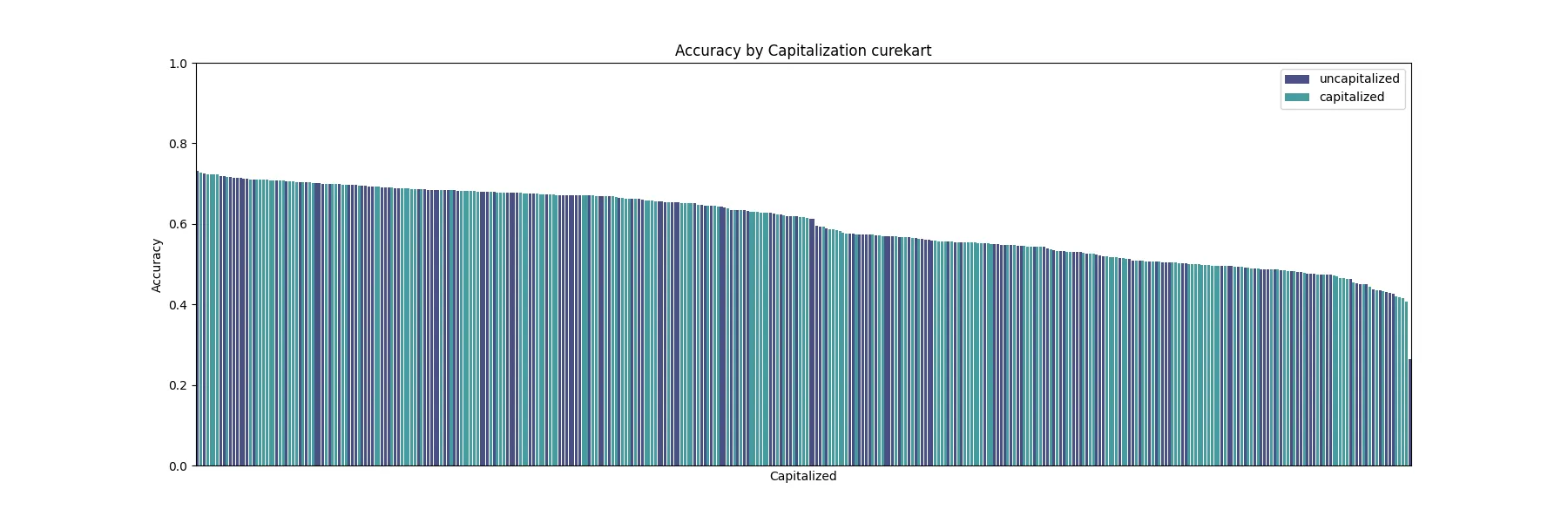
For this hypothesis we checked if adding a None intent as a description would improve classification accuracy. Below is an example for the Curekart dataset.
{
"descriptions": {
"USER_GOAL_FORM": "Add or refill goals.",
"FRANCHISE": "Becoming a franchise owner or reseller.",
"REFER_EARN": "Referral program details or ask.",
"RESUME_DELIVERY": "Delivery options or times.",
"WORK_FROM_HOME": "Ask about office open or working from home.",
"None_Intent": "When the user asks about something else."
}
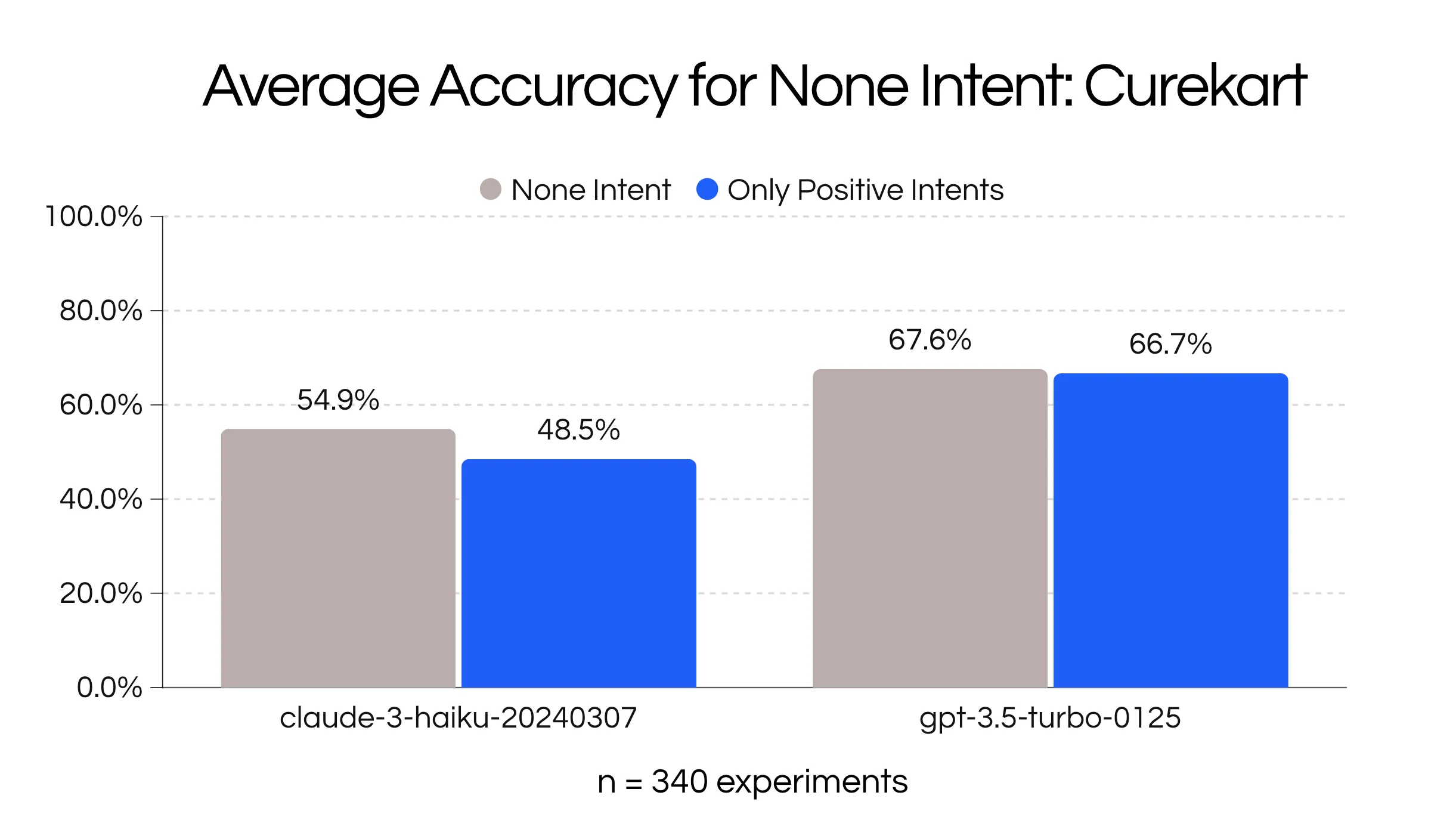
}The Curekart evaluation set is around ~50% None intents, so in theory it should improve average performance. Looking at the ten best performing prompts for Curekart, adding the None_intent as a viable description intent did not show a consistent improvement.
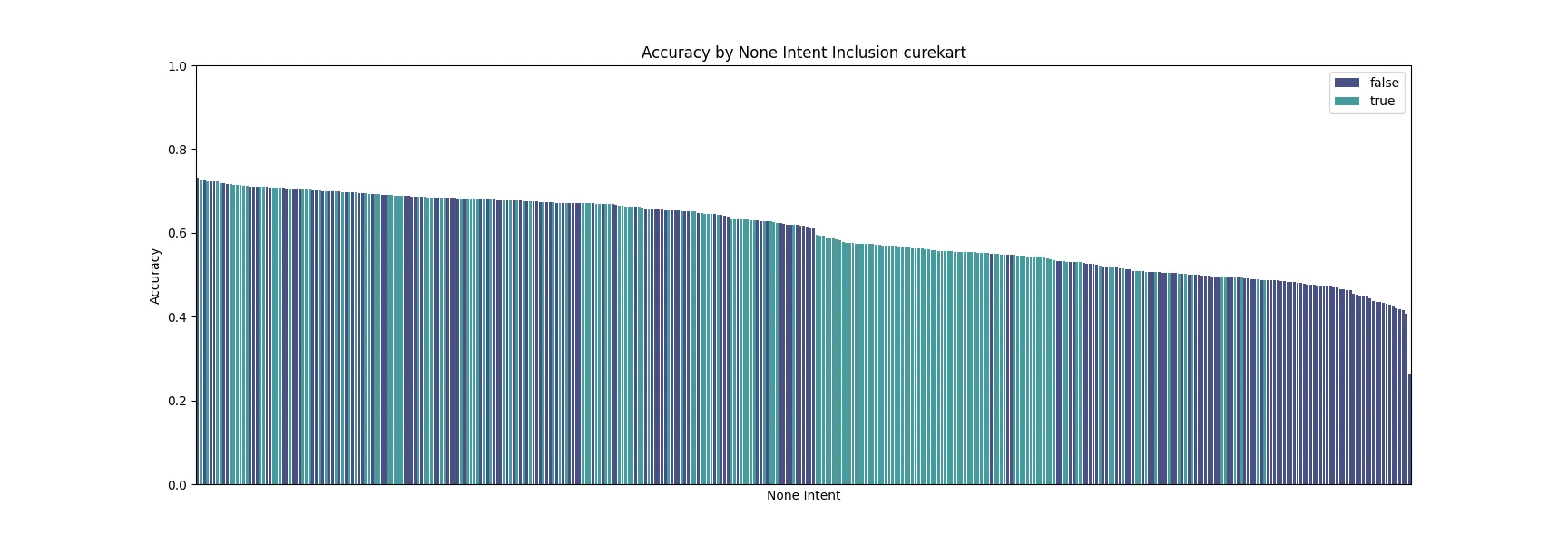
We didn’t run a None_intent check for the HWU dataset for this experiment since the evaluation dataset did not contain None.
The next hypothesis we tested was how effective using AI descriptions was for classification. Previous work has show that generating data for general LLM annotation [4] can outperform crowdsourced human annotators and can be useful to augment existing datasets for intent specific tasks [5] can be quite effective. In this experiment, we generated three descriptions using gpt-4-turbo-0419, llama-3-70b and claude-opus by using the first three utterances [C] in each intent and compared it to handwritten descriptions by the author. On average GPT-4 and LLaMa-3 performed the best.
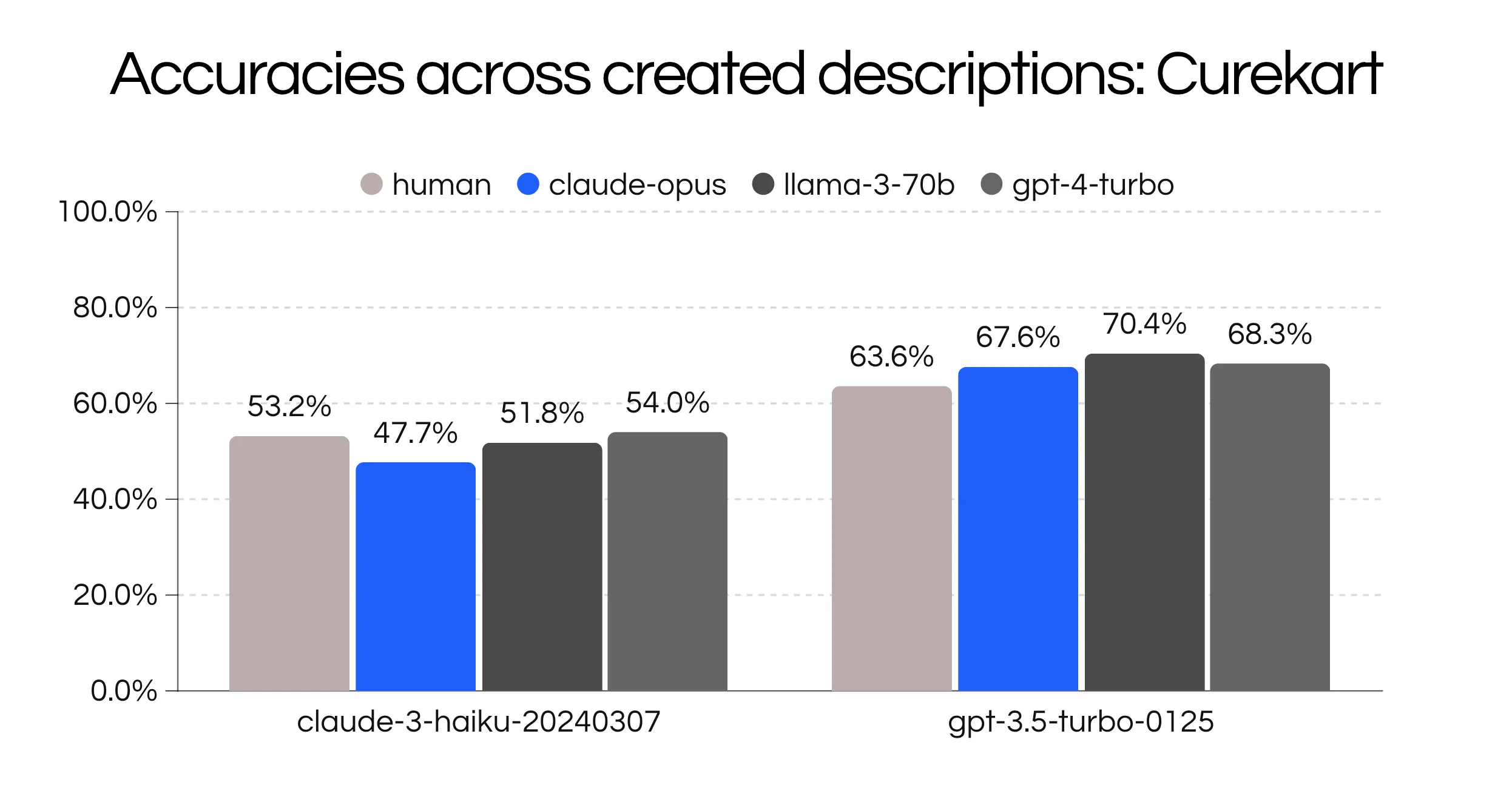
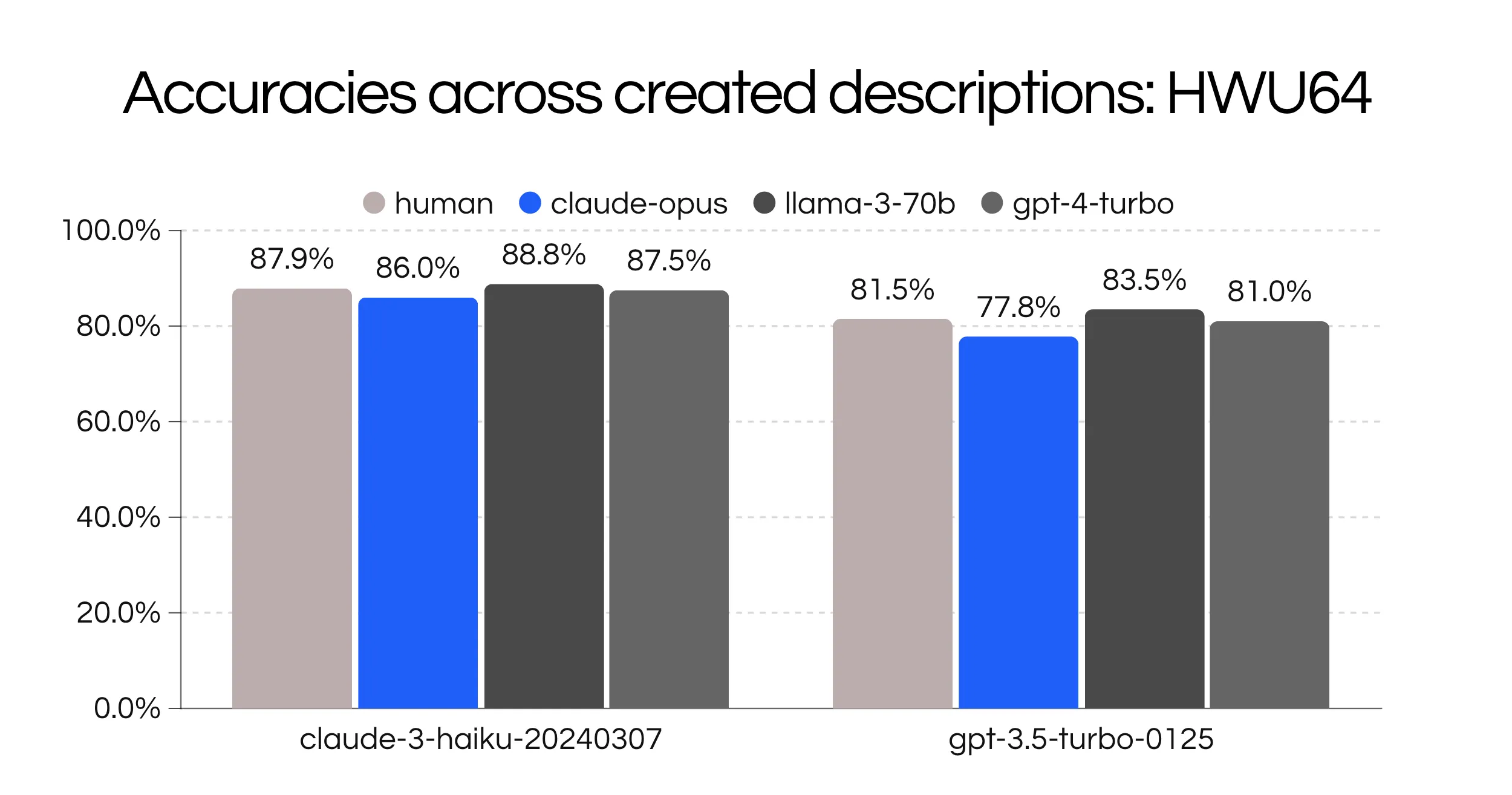
Across our top 10 combinations, LLaMa-3 and GPT-4 descriptions also performed quite well!
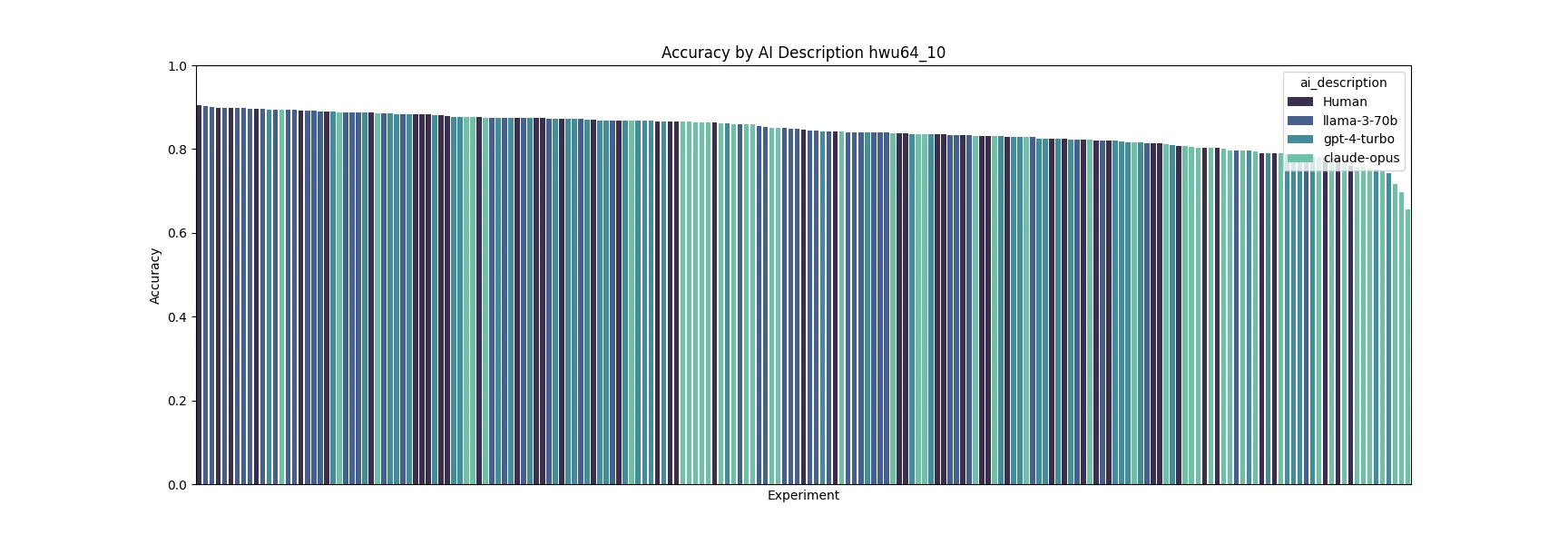
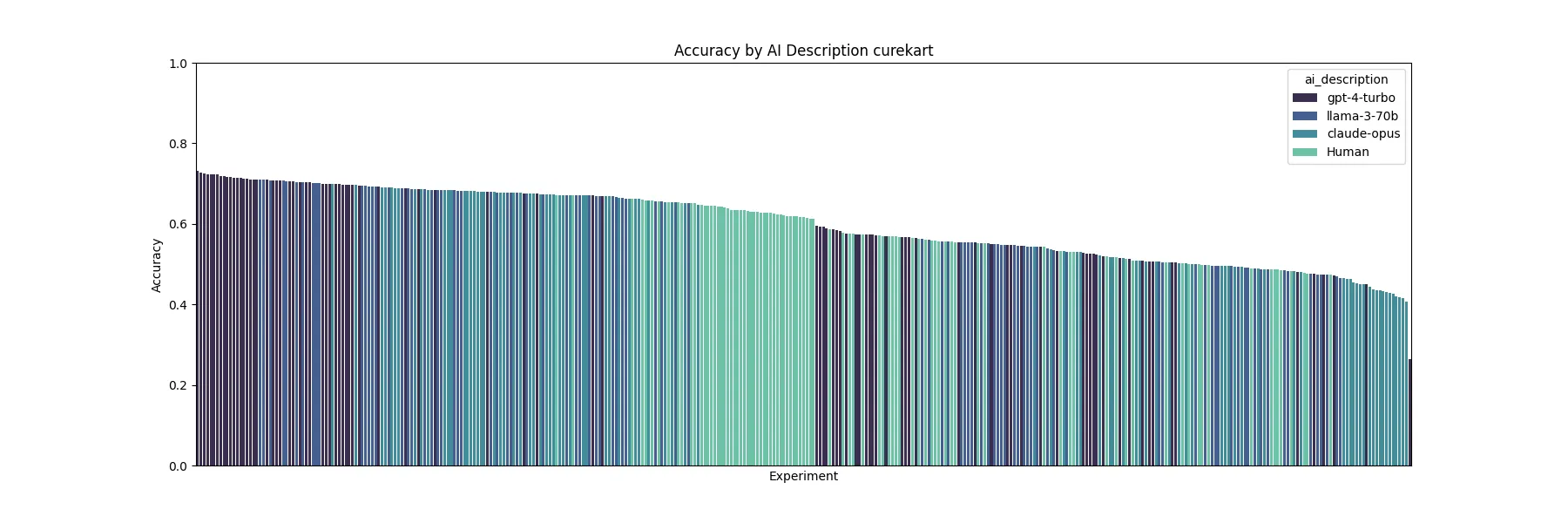
After running our initial set of experiments, we wanted to confirm that the results for better prompts were not due to noise, so we re-ran them for confirmation.
Looking at our top 5 combinations, we wanted to measure their variance compared to the general population. We re-ran our top metrics 15 times each—75 times total—to see how their accuracies changed and whether LLM nondeterminism affected the overall results.
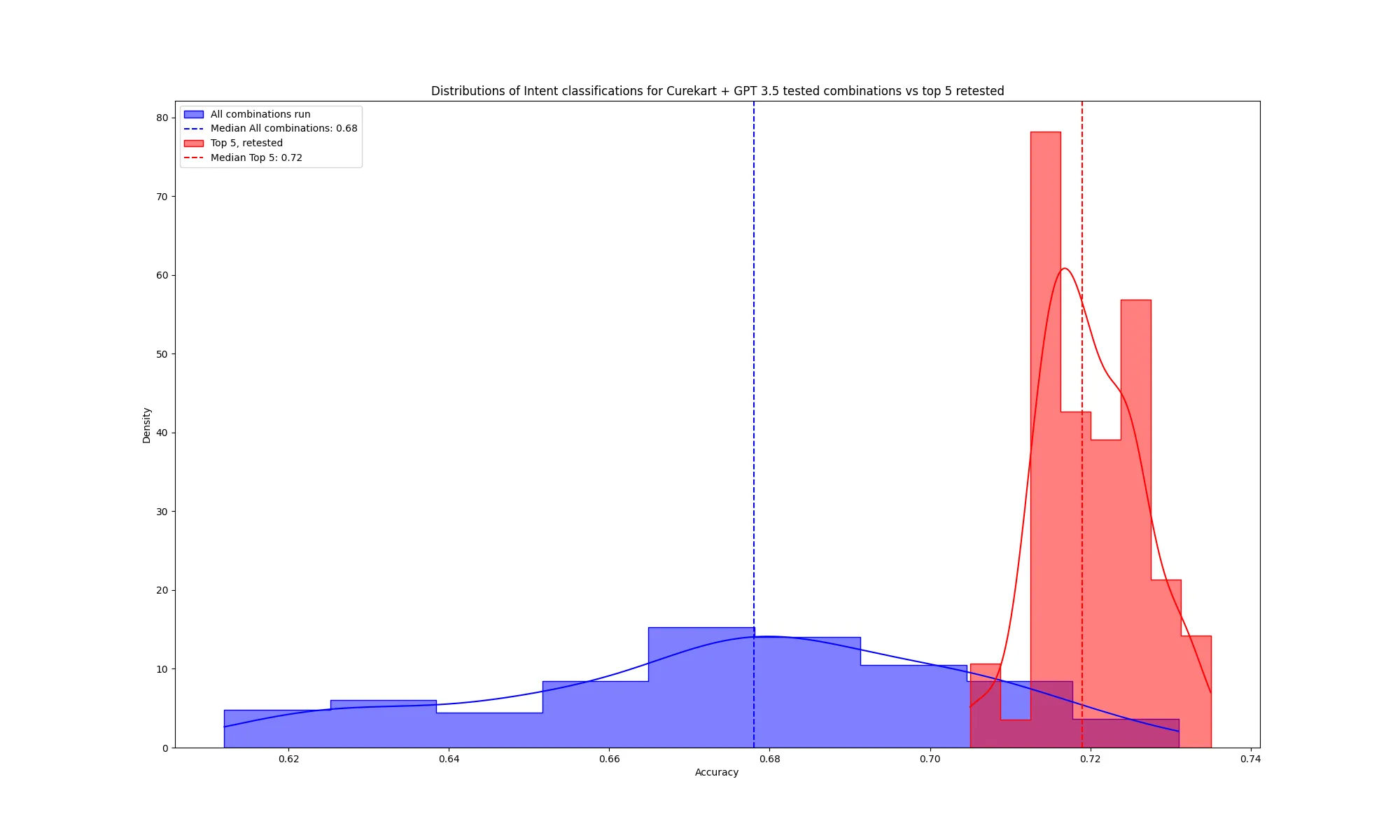
Looking at the distributions, there appears to be a measurable change. Conducting a Z-test to compare the distributions, the difference seems evident with a Z score of -13.56 and a p-value: 7.12e-42.
Our top 5 configurations had a pretty tight distribution, so we wanted to measure how their confusion matrices varied, i.e how different were the classifications. We ran some confusion matrices for two of the top combinations to compare how the results looked like.
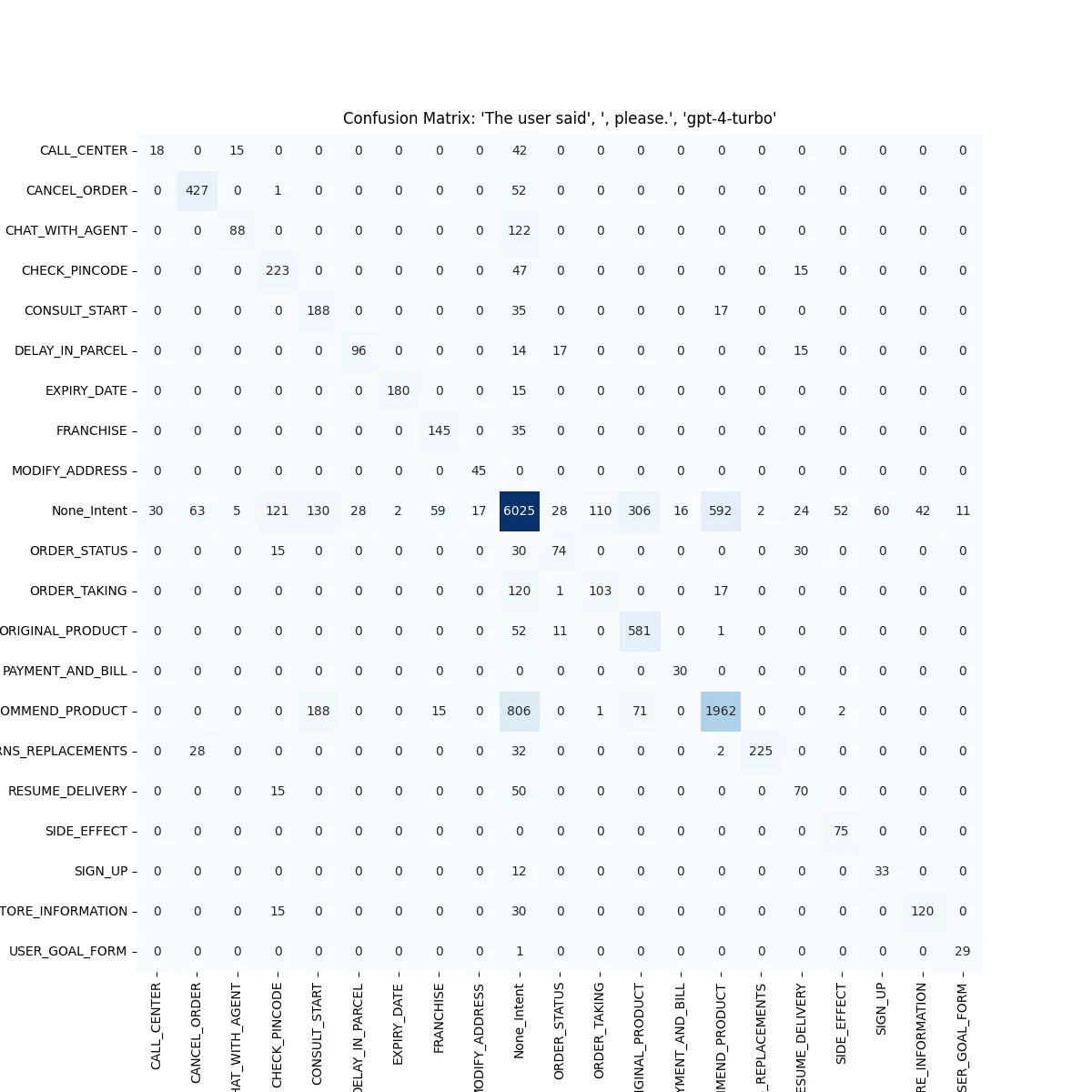
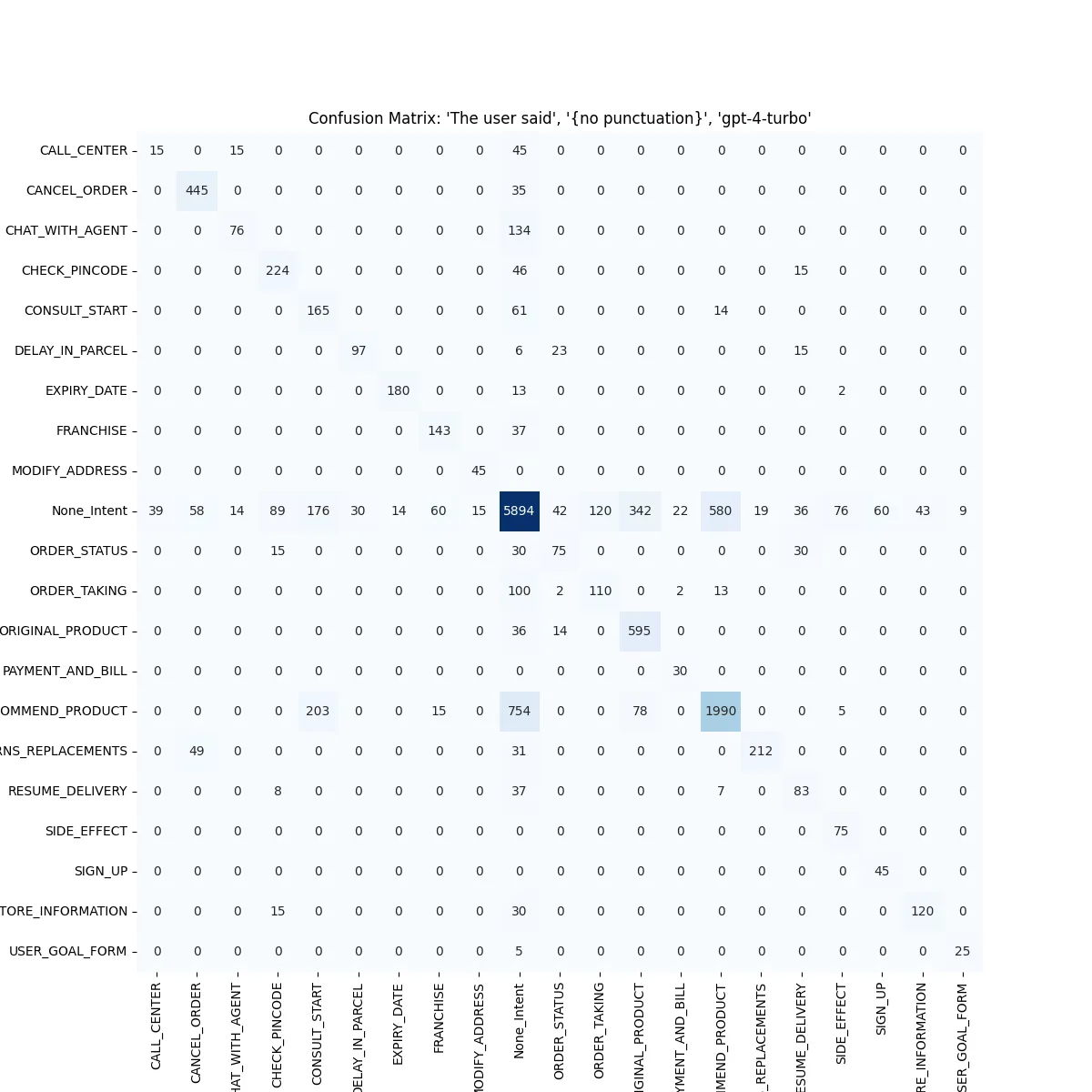
Generally, the matrices were pretty similar so we took a difference to see the performance.
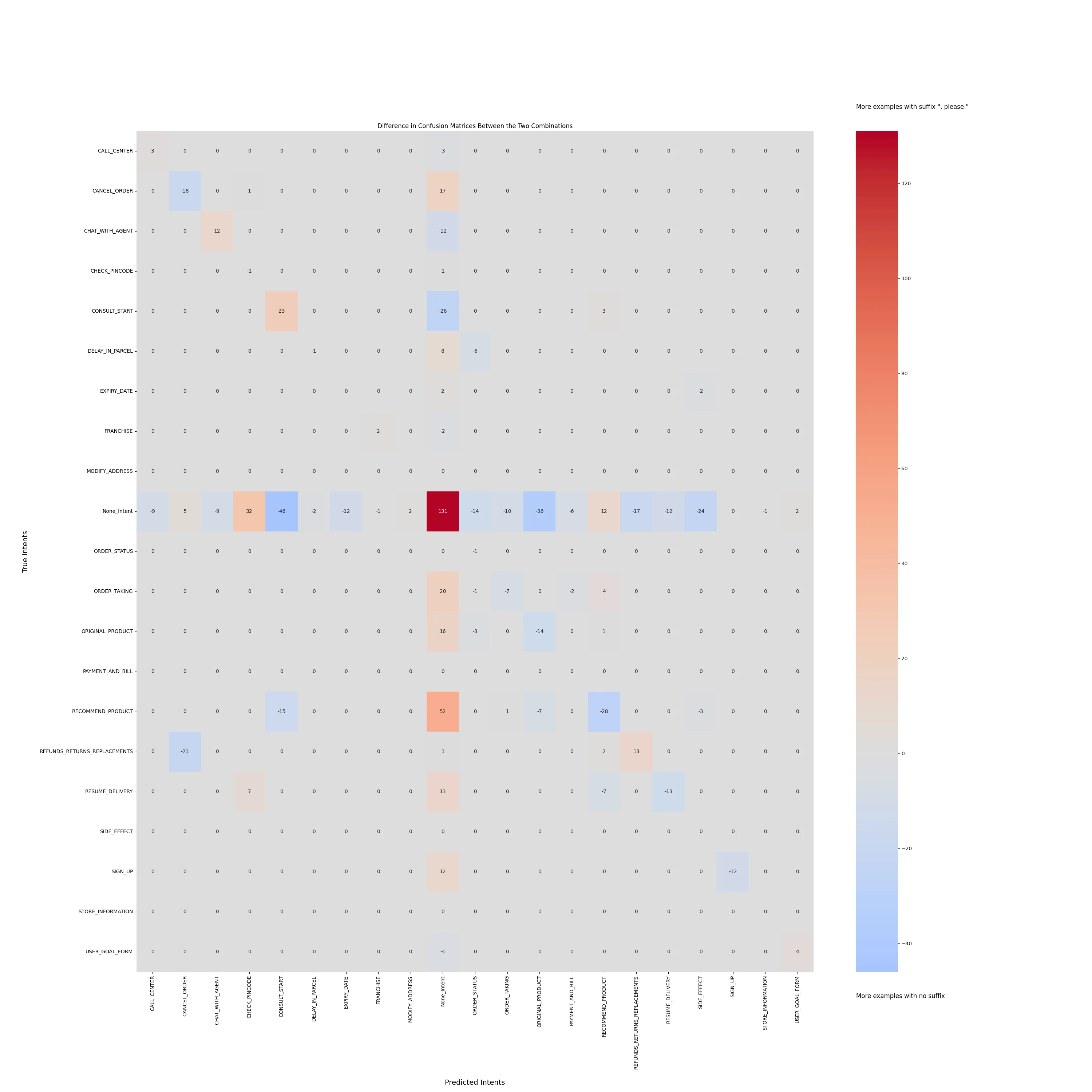
The predictions with"no suffix had a higher false-positive rate, (i.e more None intents than required), while the [please] suffix lead to more false-negative rates, (i.e more None intents predicted). On aggregate, these two modes performed pretty similarly, but a change to the descriptions led to a different type of behaviour.
Overall, changing the descriptions used for classification has small but measurable changes. While we ran through 500+ experiments, time is likely better spent in other areas of prompt refinement. In general our recommendations are:
@article{
OptimizeLLMIntentClassificationPrompts,
author = {Linkov, Denys},
title = {5 tips to optimize your LLM intent classification prompts.},
year = {2024},
month = {03},
howpublished = {\url{https://voiceflow.com}},
url = {www.voiceflow.com/blog/5-tips-to-optimize-your-llm-intent-classification-prompts}
}
Citations[1] Arora, G., Jain, C., Chaturvedi, M., & Modi, K. (2020). HINT3: Raising the bar for Intent Detection in the Wild. In Proceedings of the First Workshop on Insights from Negative Results in NLP (pp. 100–105). Association for Computational Linguistics.
[2] Xingkun Liu, Arash Eshghi, Pawel Swietojanski, & Verena Rieser. (2019). Benchmarking Natural Language Understanding Services for building Conversational Agents.
[3] Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. Chatgpt outperforms crowd-workers for text-annotation tasks. arXiv preprint arXiv:2303.15056
[4] Anders Giovanni Møller, Jacob Aarup Dalsgaard, Arianna Pera, & Luca Maria Aiello (2023). The Parrot Dilemma: Human-Labeled vs. LLM-augmented Data in Classification Tasks. In Conference of the European Chapter of the Association for Computational Linguistics.
[5] Gaurav Sahu, Pau Rodriguez, Issam H. Laradji, Parmida Atighehchian, David Vazquez, & Dzmitry Bahdanau. (2022). Data Augmentation for Intent Classification with Off-the-shelf Large Language Models.
[6] M. Sclar, Y. Choi, Y. Tsvetkov, and A. Suhr (2023). Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting. arXiv preprint arXiv:2310.11324, 2023.
[7] Linkov, D. (2024). How much do ChatGPT versions affect real world performance? https://www.voiceflow.com/blog/how-much-do-chatgpt-versions-affect-real-world-performance
Code to Generate descriptions
def first_three_utterances():
import json
label_file_path = 'train/label'
seq_in_file_path = 'train/seq.in'
# Read the complete files
with open(label_file_path, 'r', encoding='utf-8') as file:
labels = file.readlines()
with open(seq_in_file_path, 'r', encoding='utf-8') as file:
utterances = file.readlines()
# Remove any extra whitespace
labels = [label.strip() for label in labels]
utterances = [utterance.strip() for utterance in utterances]
# Create a dictionary to hold the intents and their utterances
intent_utterances = {}
for intent, utterance in zip(labels, utterances):
if intent in intent_utterances:
if len(intent_utterances[intent]) < 3:# Collect only the first three utterances
intent_utterances[intent].append(utterance)
else:
intent_utterances[intent] = [utterance]
# Convert dictionary to JSON
json_output = json.dumps(intent_utterances, indent=4)
print(json_output)

.avif)
.avif)


