Voiceflow named a 2026 Best Software Award winner by G2
Read now
If you’ve used the ChatGPT API before, you’ve likely noticed different model versions associated with them. The original ChatGPT API was released March 1st, leading to a naming convention of gpt-3.5-turbo-0301. Next came gpt-3.5-turbo-0613, gpt-3.5-turbo-1106 and as of this article’s writing, gpt-3.5-turbo-0125.
After the initial gpt-3.5-turbo-0301 release, it was challenging to predict the impact of each of these versions; Open AI did not release new benchmarks for each and did not disclose major changes. LLMs are also non-deterministic, making it difficult to measure the impact of such a change. So, from a high-level perspective, something shifted with these models due to a version upgrade, but it wasn’t clear what the consequences were.
Once gpt-3.5-turbo-0613 was released, there were a few papers published looking into task-specific aspects of this model version change[1], but they mainly focused on small tasks like prime-number detection that are usually inconsequential to a real-world use case.



Many of these tasks were also 0-shot based, rather than few-shot-based which is the technique that creates formatting and response stability that production applications look for. Over the course of 2023, more research was conducted on the overall sensitivity of prompts showing dramatic differences across models with small tweaks in prompt formats. [2]
While ChatGPT and LLMs changed the narrative around building AI Agents, intent classification remains an important problem for directing user conversation and structuring agent actions.
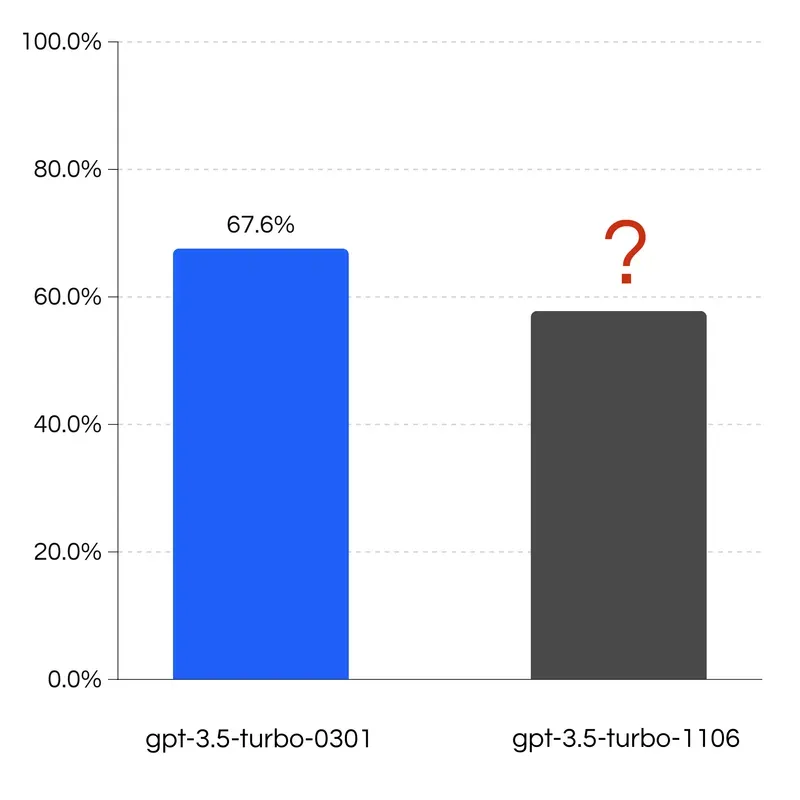
In late 2023, we were working with a customer who was using LLMs for intent classification and noticed that gpt-3.5-turbo-0301 was getting close to end of life. So, we upgraded this customer’s base model to gpt-3.5-turbo-1106, and it dramatically decreased the performance.
After realizing the impact of our change (and reverting), we retroactively ran the benchmarks and saw the severe degradation on the newest model of ~10%*.
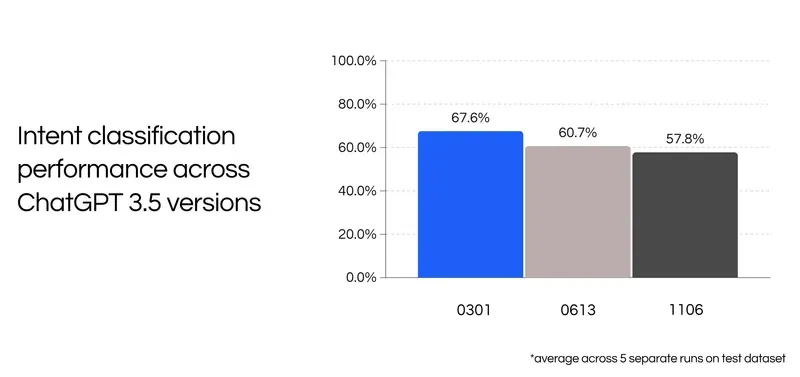
With this degradation in mind, we decided to tweak the initial prompt slightly to improve model performance back to our initial benchmarked accuracy. At face value, the changes are not apparent, but make an impact.
To improve our prompts and reduce version discrepancies, we iterated on one portion of our real-life dataset to improve our validation accuracy and find a prompt that brought *gpt-3.5-turbo-1106’*s accuracy to an acceptable range.
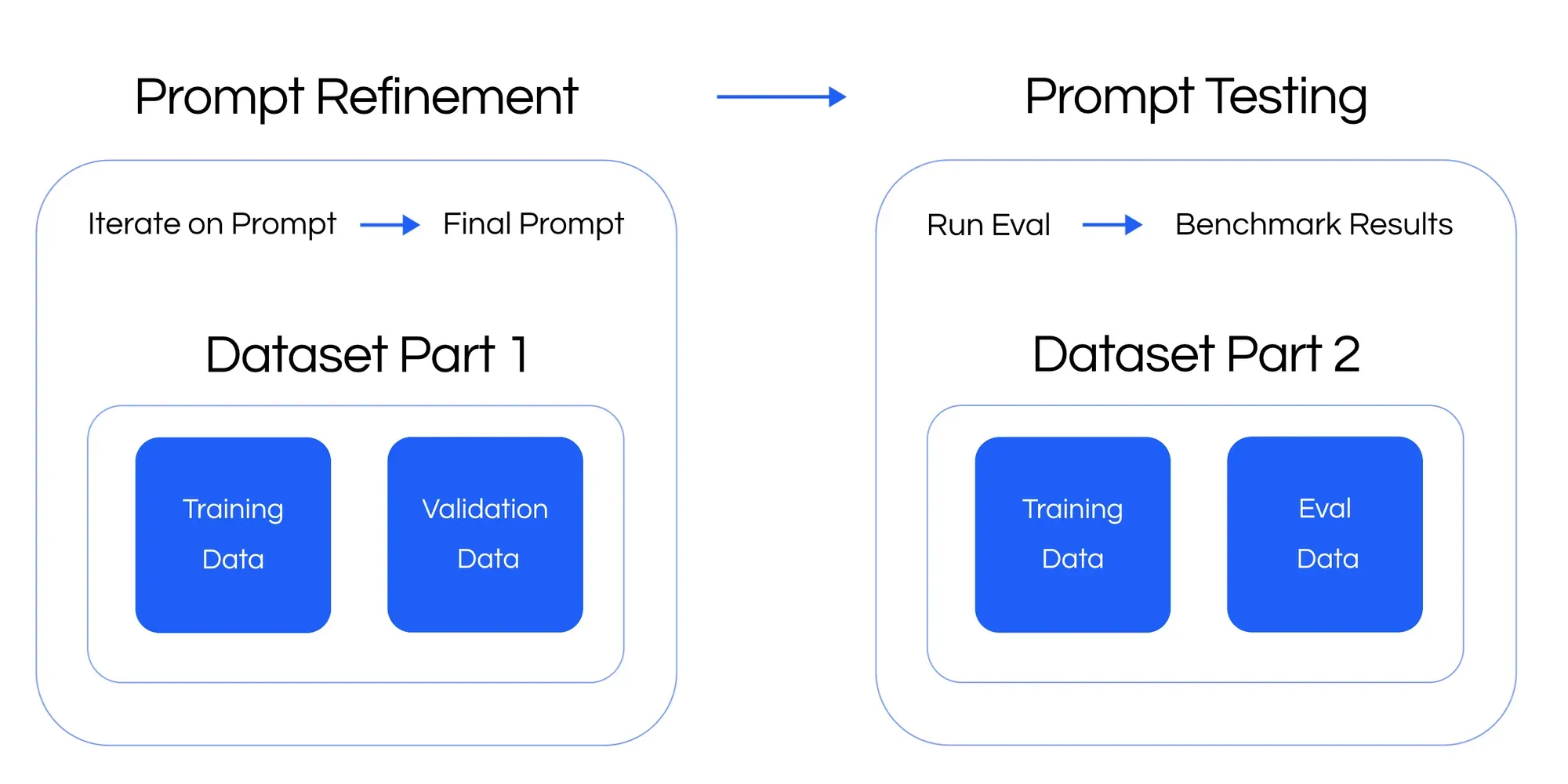
After the iterations, we ran our evaluation dataset** once and confirmed that model results were much better for gpt-3.5-turbo-1106*** (and gpt-3.5-turbo-0125 a few months later for curiosities sake).
Our final prompt had three main changes:

To measure the impact of each of these changes, we ran a small ablation study to measure the impact across each change.
Our goal with ablations was to gain a better insight into the magnitude of each change’s performance.
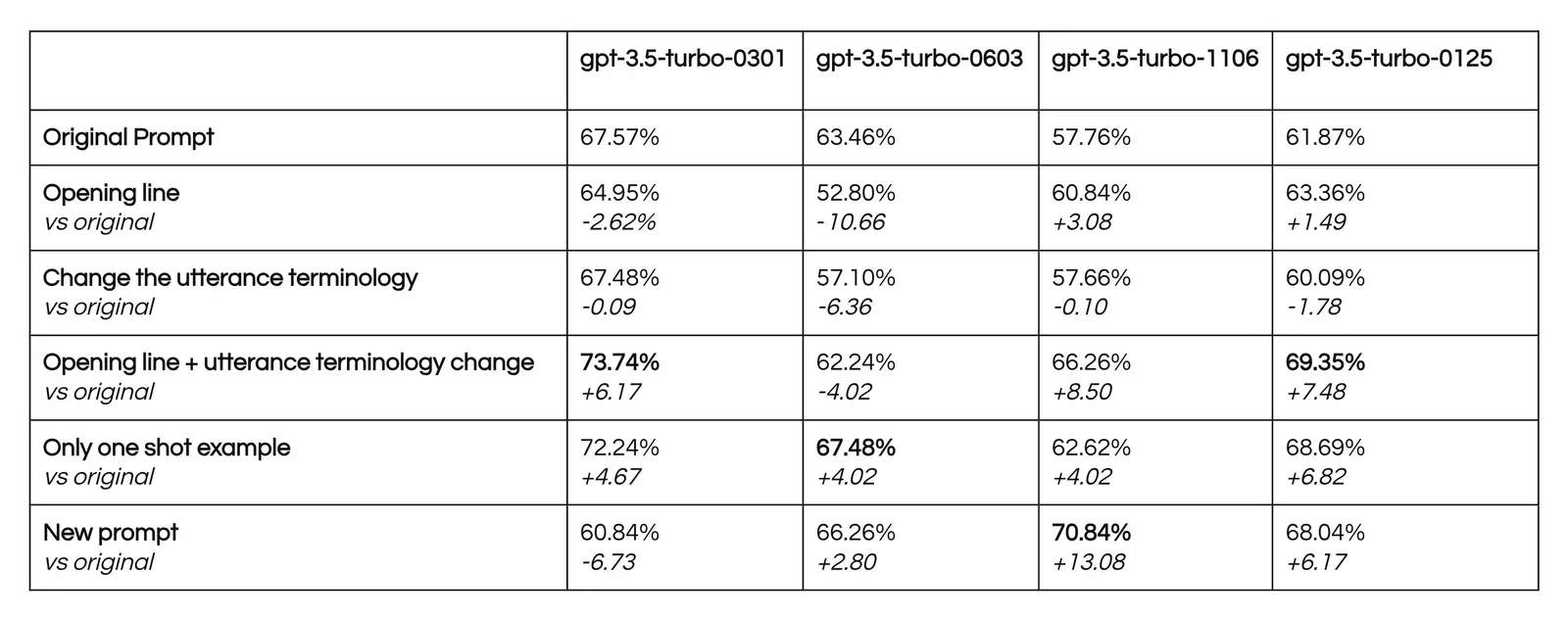
The ablations generally improved performance for later models and demonstrated impact of -10.66% to 13.08%. Bolded results show the best performing ablation for each model. Interestingly enough, the ablations performed better on later models showing a higher impact across techniques. However, there was significant swings for seemingly small changes showing the brittle nature of prompts.
With our three prompt modifications, our intent classification task performed much better on newer models. The accuracy decreased for the initial gpt-3.5-turbo versions, but increased across most recent versions.
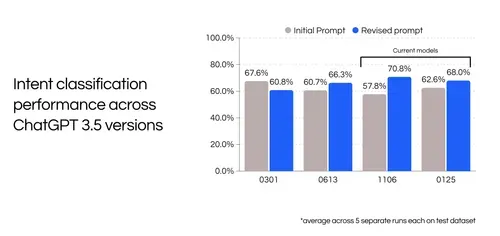
LLM versions can make a large difference! Even for a few shot approach. Having good, non benchmark datasets to validate performance is important, even when onboarding new use-cases. In the future we’ll be discussing some our techniques for internal prompt optimization!
The Voiceflow research section covers industry-relevant and applicable research on ML and LLM work in the conversational AI space.


.avif)
.avif)


