Voiceflow named a 2026 Best Software Award winner by G2
Read now
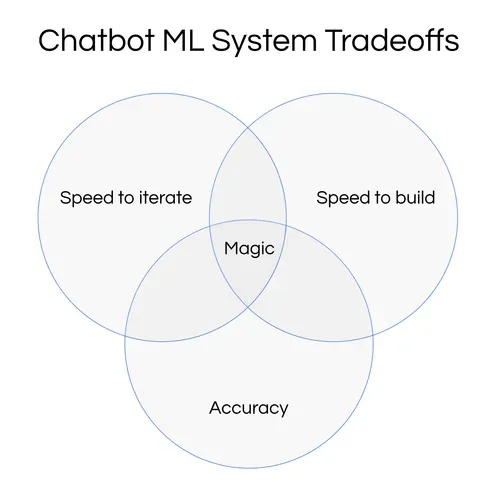
When building ML systems, tradeoffs will always occur. The important thing is to be aware of tradeoffs and finding ways to mitigate their downsides. In the conversational AI space, going from user question to response is a hard problem, so we usually create intermediate steps.
Currently, one of the important components of a good conversational agent is intent matching, or routing user utterances down the right conversation path. Using a generative or classification both require a deep understanding of customer behaviour and a comprehensive training dataset. This becomes more challenging when considering a real world scenario, where user behaviour involves many out-of-distribution questions [1]. To address this long tail of questions, we can implement a RAG-based architecture to form an answer based on domain knowledge, (an architecture we launched in May 2023).
In a conversational AI space, if you choose to use an intent-based architecture, you’ll need better classification. In our case study today we’ll cover:

The Customer Support Agent
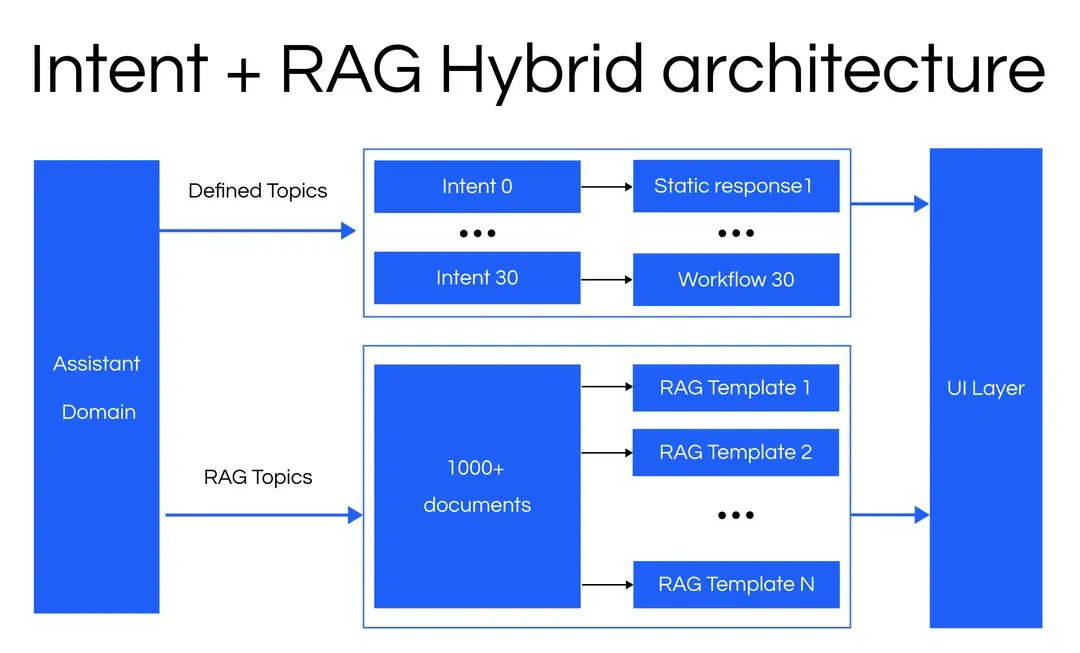
Our customer was looking to launch a brand new customer support agent. They had a deep understanding of the customer questions and were building the assistant to match this understanding. To design the system, they defined thirty well-labeled intents and thousands of implicit intents through a RAG-based system. The goal of the system was to use explicit intents when information was well-defined and stable, and a RAG architecture for answers to a high volume of product questions that would change often.
This demonstrates a common tradeoff in real-world ML system design; speed to build, accuracy, and speed to iterate. You can throw more money at the problem, but then your system may no longer be ROI positive.
In this case, the customer’s AI strategy focused on a quick time to market and a desire to iterate rapidly. To accomplish this, they opted for an intent structure for well defined flows and a RAG architecture for a long tail of product questions. This architecture was fast to build, easy to update and scale, but more vulnerable to distribution changes and real-world phrasing. After a few weeks in production, we worked with the customer to address this by improving the intent classification and RAG components of the platform.
Like many ML/AI projects, after running the agent in production for a few weeks, testing performance and production performance diverged from initial results. With out-of-domain questions (OOD), many benchmarks have much lower accuracy scores compared to those in domain [1], so the accuracy scores mentioned here will be within that range. These reflect many real world scenarios in the development phase compared to benchmarks on standardized datasets.
To help address the issue, we investigated a few avenues to help the customer improve performance: augmenting training data, using an LLM hybrid system, or creating more specific intents. We iterated using two parts of a dataset, which were labeled by our customer due to the nuance of the product categories.
After investigating a number of techniques, we ran benchmarks on both the validation and eval datasets.
The validation and evaluation set distributions are quite different from the training datasets, something many bootstrapped ML use cases face.
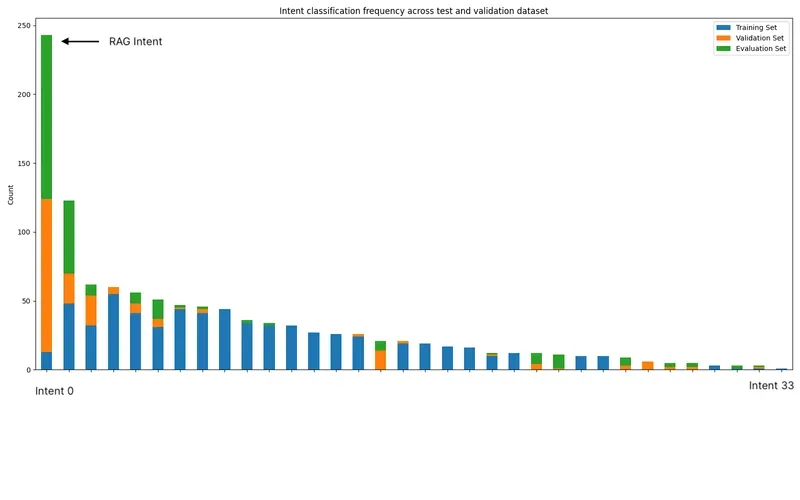
After iterating with the training dataset, we improved validation accuracy by 23%. Macro F1 scores also improved, but were quite low given certain infrequent intents (>3 test set occurrence) having scores close to 0. However, the lift of 23% accuracy and hand inspection gave us confidence of the effort. We also analyzed other methods, which we’ll cover in future articles.
After the validation set optimizations, we ran our final changes on the evaluation set, showing that results generalized well with 14% accuracy gain.
While diving deeper into the validation dataset, we saw that many intents could be split into smaller ones to get more specific decision boundaries. Peter Isaacs, our lead conversational designer, led this effort having worked on similar projects in the past four years.
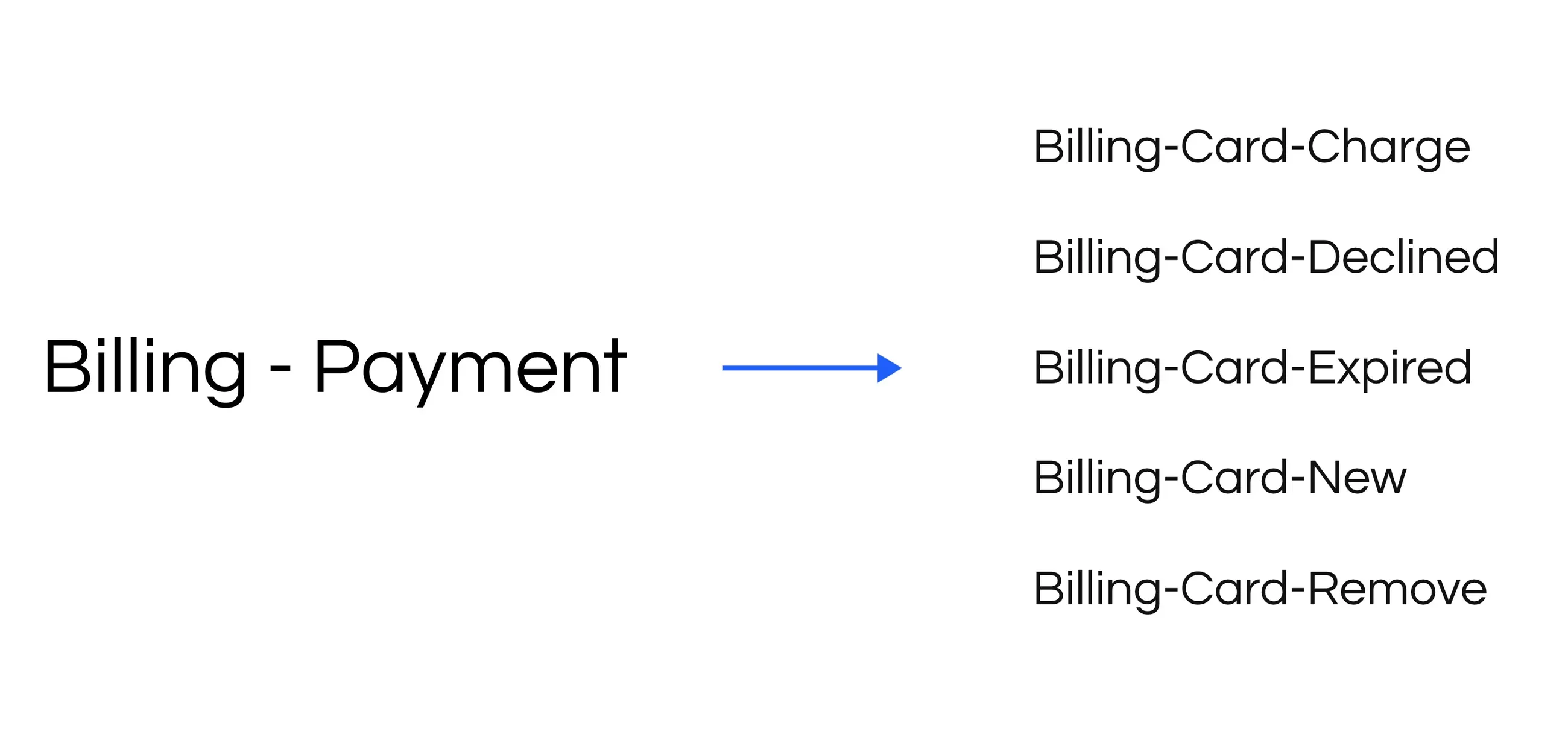
After splitting the intents we went from thirty four to fifty two intents, capturing the key concepts from the validation and training datasets.
One of the challenges of classification problems is classifying out-of-domain data. For example: if you have two classes—fruit and vegetable—and a user asks about cats, you get a non-sensical classification. To address this challenge, you can add a fallback, none intent, or confidence score threshold. In our NLU/RAG hybrid architecture, we can also fallback on RAG to try to answer the question with an additional relevance filter.
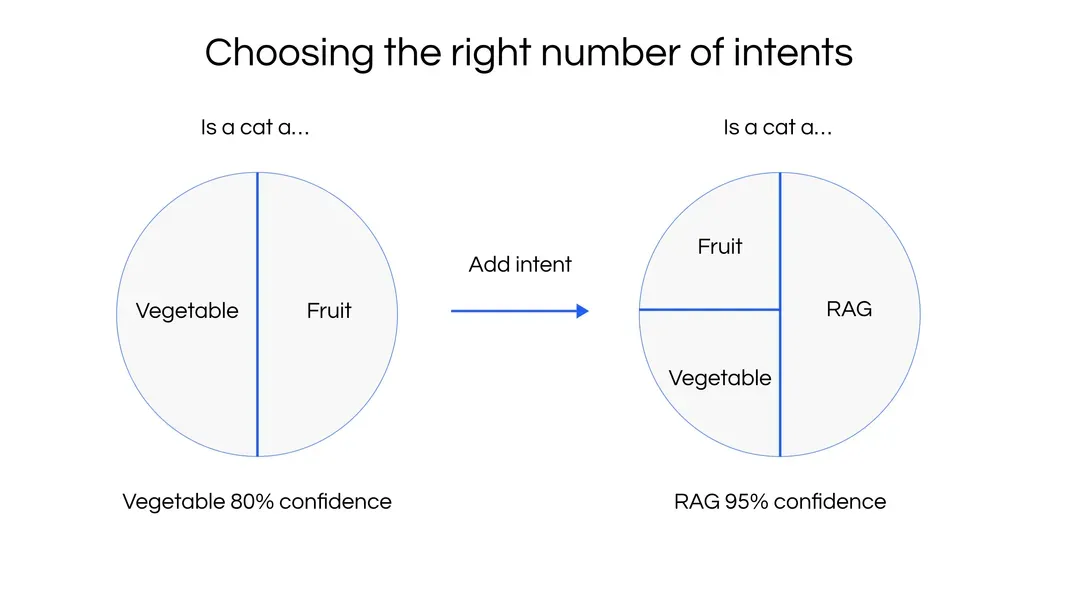
Likewise, when more relevant questions are asked, having more close classes will reduce the classification confidence of out-of-distribution queries. Overdoing this may also cause this model to overfit. Our NLU system uses a softmax approach, which means that confidence levels will be magnified if they’re not very close together.

Generally these types of experiments would be conducted internally within a data science team, but our goal is to productize these optimization techniques to help teams launch conversational AI more easily.
Building Conversational AI systems requires understanding tradeoffs and strong domain understanding. Initial launches require iterations, especially as usage patterns become more known. Adding more specific intents can increase performance in this architecture. We will be diving deeper into other techniques in future articles.
The Voiceflow research section covers industry-relevant and applicable research on ML and LLM work in the conversational AI space.


.avif)
.avif)


