Voiceflow named a 2026 Best Software Award winner by G2
Read now

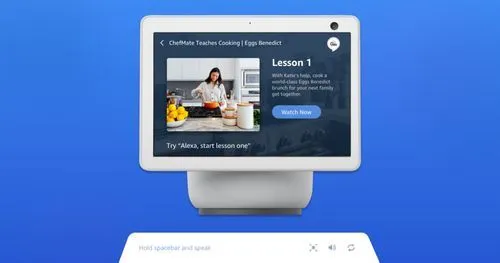
Multimodal interfaces combine smart displays with smart speakers. At a high level, they provide the user with the ability to interact with a system using multiple modes of input (ex. voice control, voice command, touch screens) and output (speech synthesis, graphics, pre-recorded audio). Popular examples of multimodal interfaces include smart home devices like Amazon Alexa and the Google Assistant.
As smart home speakers and virtual assistants continue to increase in popularity, many users are adopting new user interfaces. This includes in-car assistants, Alexa skills, and multimodal texts, to name a few.
The customer experience is shifting as a result. No longer is it just about purchasing a great-sounding speaker on Amazon or at your local big-box store. It's about intertwining it with machine learning and a combination of visuals and text to create a multimodal experience tailored for every scenario.
Conversational interfaces have now evolved to provide a deeper selection of devices that include screen, touch and voice. From the lens of a conversation designer, it's important we apply what we've learned from voicebots like Alexa and Google, as well as chatbots like Facebook Messenger to better adapt our voice designs to accommodate GUI interactions.
For example, you own a Google Nest Hub Smart Display and want to play a song from Apple Music. To invoke this action, you might say, "Hey Google, play music." The device then initiates your command by considering your previous history of choosing Apple Music as your go-to music provider. Once it opens the app, it begins to radiate music from your Echo Show.
Since it's a smart display, the Echo Show uses a graphic to illustrate the song that's currently playing while also presenting a variety of interactive voice and touch features for the user to engage with. (i.e. changing the track, stop/play, save to playlist, etc). This results in a user-friendly interface that is easily adaptable to a variety of contexts.
A significant number of our users are already building multimodal experiences - whether for Alexa (i.e. Echo Show), Google, or other conversational assistants. These users need multi-layered designs to create these experiences in their entirety.
Well-known conversation designers Diana Deibel and Rebecca Evanhoe neatly summarize the value of designing for multimodal interfaces in their book Conversations with Things.
“By allowing more than one type of input or output, multimodal interactions provide an experience that aligns more closely with how humans typically interact with the world.”
Our team at Voiceflow wants to support this workflow by providing the tools to build for different modalities.
If we try and project the future based on what we know, we can expect every conversation assistant in 1-5 years to be a multimodal experience. Conversation design will be so much more than crafting voice inputs and outputs, leading us to a place where it will become mandatory to design that cohesive experience across all modalities.
With that said, we want Voiceflow to be able to provide that expanded view of what conversation design is.
Where is the user? What are they trying to accomplish? That is the primary consideration when you're thinking about multimodality.
For example, if a user is interacting with your music service while sitting at their desk vs. driving in their car, their context is vastly different. Their safe methods of interaction are much different.
What type of context do you want to deliver to them verbally vs. visually? What interactions do you want to activate using touch? All of this will change based on their context of use, such as where they are and what they're doing at that given moment.
When thinking about how you're designing skills or assistants, you need to be able to mix and match the inputs and outputs to align with the needs of the user in a number of scenarios.
In her book Design Beyond Devices, well-known interaction designer Cheryl Platz explains that we need to account for change when designing for multimodal experiences.
"The highest risk and greatest challenge in multimodal design lie in the transition states. Transition can take many forms in advanced experiences: (1) changing input or output modalities, (2) switching devices during a single, end-to-end task, (3) multiple customers sharing a single device. Design of a truly multiple modal system will require you to look between moments."
- Cheryl Platz, Design Beyond Devices
Designers are going to have to take a customer-centric approach to conversation design and first answer questions like, what are all the applications? How are they going to want to interact with my assistant in different situations?
The next step is effectively designing these variants of the user experience specific to each context as well as the transition that occurs between them.
What does this mean for designers and design teams?
Ultimately, their skillsets will need to expand as it's no longer solely about designing verbal inputs and outputs. It's about learning how to design for the multimodal or visual interface. It entails determining how the visual interface interacts with the context provided by the speech interface, as well as how these different forms of interaction are in harmony with one another.
The most significant impact being made with multimodal conversational assistants right now is in-car applications.
By nature, when a user is driving a car, minimizing distractions is paramount to ensuring the safety of the driver and those in the vehicle. In-car assistants have done a very good job of delegating the following:
Today's in-car assistants try their best to lower the user's cognitive load to make completing a desired task as simple as can be. They also ensure that anything done visually can be viewed at a glance, and anything requiring a higher cognitive load can be executed verbally. And so the balance between these three different modalities - voice, visuals, and touch - have been handled very thoughtfully by in-car assistants.
We've started to see great applications of multi-modal skill design for Alexa in the last year. Some examples include games like Star Finder and Mighty Cards. Although voice interactions primarily drive these skills, the depth of these experiences wouldn't have been possible without a visual layer. The interactions are kept fairly simple, but both games have achieved incredibly high levels of engagement due to the sheer amount of visuals involved.
With an existing mobile application, layering speech input is another way to help focus a use-case around voice. Since you already have an application's existing functionality, implementing voice focuses in on two things: enhancing the user experience with new functionality and/or replicating parts of the user experience that could be better fulfilled via voice.
An example of this is Snapchat's Voice Scan - where you're able to search and select filters with your voice. This is a great example of voice being the better input for a particular function since there are thousands of filters to choose from.
Using your voice, you can quickly search and select filters instead of endlessly scrolling down a list or typing into text fields.
Further supporting Snapchat's choice of input, this experience is largely performed with the phone held away from your body where the user is not in a typical typing position.
This is why Snapchat decided against visual input modality here, as it offers an inferior user experience. Instead, the company settled on voice since it offers the biggest benefit when considering the context.
Conversational assistants will become more popular in the future. The places they are deployed and the specific use-cases for them will open up the same opportunities for multimodal.
Before the pandemic, many of our daily experiences were mostly transactional - information in, information out. This include things like customer support, ordering from fast food restaurants, paying gas, and asking the bank for account info. Quick exchanges of known information facilitated by asking the right questions.
In the not-so-distant future, these experiences will be supplemented with conversational assistants. For multi-modality, the opportunity here is how you can add varying layers of context to those conversations through banking assistants.
For example, if you say to a bank teller, "I need to send a wire transfer," there's a lot of additional context below the surface of that statement that isn't communicated. This includes the account it's coming from and your current balance.
Since this information isn't going to be communicated unless asked, there's an immense opportunity to include these additional layers of context so that it can be leveraged by either side (human or assistant) to ensure a more successful outcome. Using visuals, you can deliver supplemental context (i.e., the display could show your accounts/balances) that doesn't necessarily need to be inserted into the interaction. Instead, it can be serviced or brought into the conversation as needed or when called upon.
In transactional use-cases, there is significant potential to include additional levels of detail to these conversations, so that it can be leveraged by a person or conversation assistant.
There's two sides to this conversation.
Conversation designers need to start thinking about how they can bring visuals and multi-modalities into their work. At the same time, visual/UX designers need to begin asking themselves how to bring conversation design into their work.
Right now, conversation and visual/UX designers generally act as two different roles within organizations. As experiences become more and more multimodal in nature however, there's going to be a merging or partnering of these functions. We may even see 'unicorn designers' appear - individuals who have excellent UX and conversation design skills.
This is to say that we're moving in a direction where there is little distinction between visual UI/UX and voice UX. Eventually, it may be grouped as 'design' or the user experience as one all-encompassing discipline.
So, how will this work change moving forward?
You're going to have to have consideration for the entire user experience right out of the gate. That means designing a customer journey to an outcome and then mapping how those interactions come to life using a combination of modalities.
It's not a case of designing voice-first and then layering on graphics, since this approach might not be appropriate in certain contexts. It's about having an eye for the user experience. Where you can determine the best UX regardless of modality, and then afterwards, carefully apply the specific job or task in the user journey to the modality that works best.
As conversation design becomes more of a multimodal practice, it will increase the visibility of the role.
Right now, it's difficult to demonstrate or share voice user experiences within the design community or on social media. Because of this, a lot of the great work that's being done by conversation designers today doesn't necessarily have the audience that it could - or should.
For example, It's really hard to show-off an in-car assistant when viewing a flowchart in Voiceflow. It's only after having a multimodal prototype that differentiates channels that really makes these experiences come to life and look good.
As experiences become more interactive and multimodal, they will become more shareable in the design and product world. This means there is a big opportunity for multimodal conversation designers to get the attention they deserve for their work, as it becomes more consumable for the broader audience.


.avif)
.avif)


