Voiceflow named a 2026 Best Software Award winner by G2
Read now
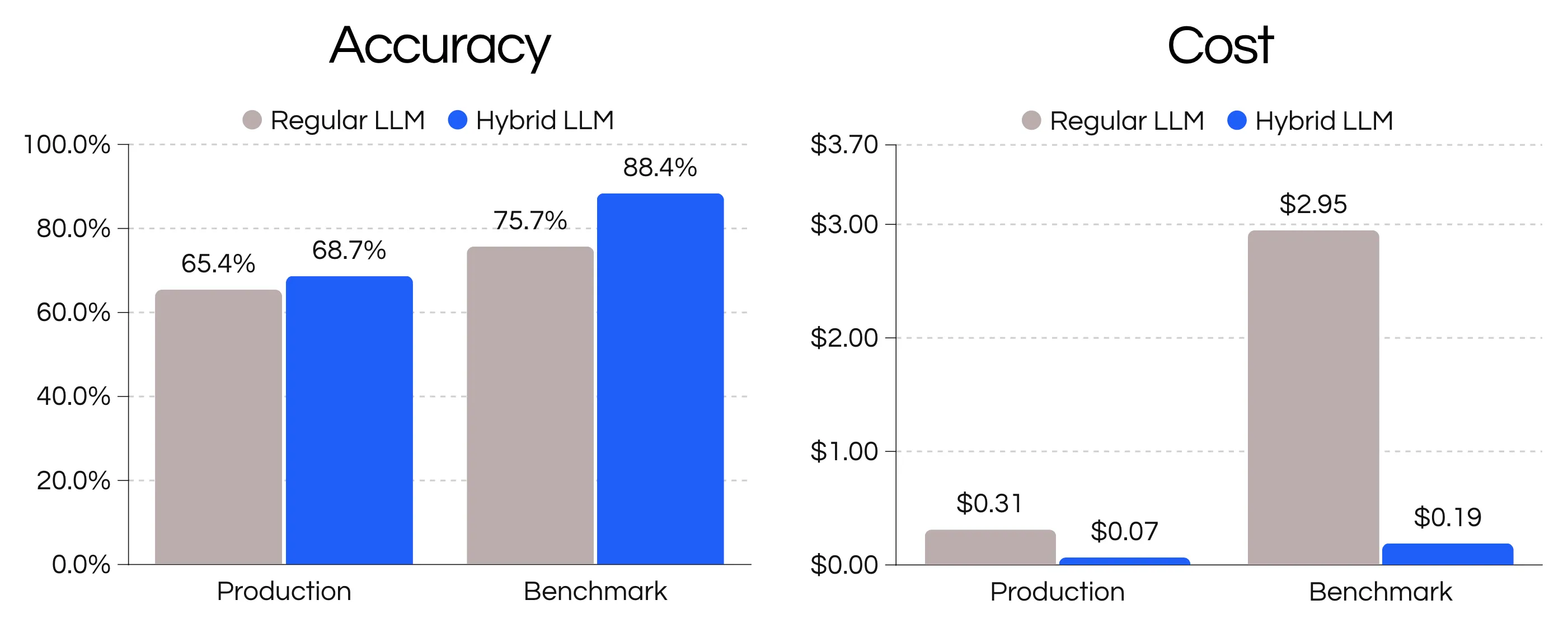
Improving intent classification is an important task in the conversational AI space. In this blog post, we analyze the benefits of using a hybrid NLU/LLM intent classification architecture across small, medium, and large conversational AI datasets. After testing this solution in production with a small cohort for four months, it outperforms NLU models for smaller datasets and slightly outperforms full LLM solutions for 3x-5x lower costs for larger datasets. We also find that state-of-the-art models don’t always outperform older models and performance is heavily dataset-dependent. We examine these performance, cost, and UX benefits in the following sections.

For the past 10+ years, conversational agents have relied on intent classification via NLUs to determine next steps in the conversation. This paradigm powers billions of conversations around the globe daily — and millions on Voiceflow. While this feels like a legacy architecture compared to fully generative assistants, it’s still commonly used in LLM applications, often rebranded as semantic routing.
When deciding how to utilize LLMs to their best ability for intent classification, we set out to experiment through a number of constraints:
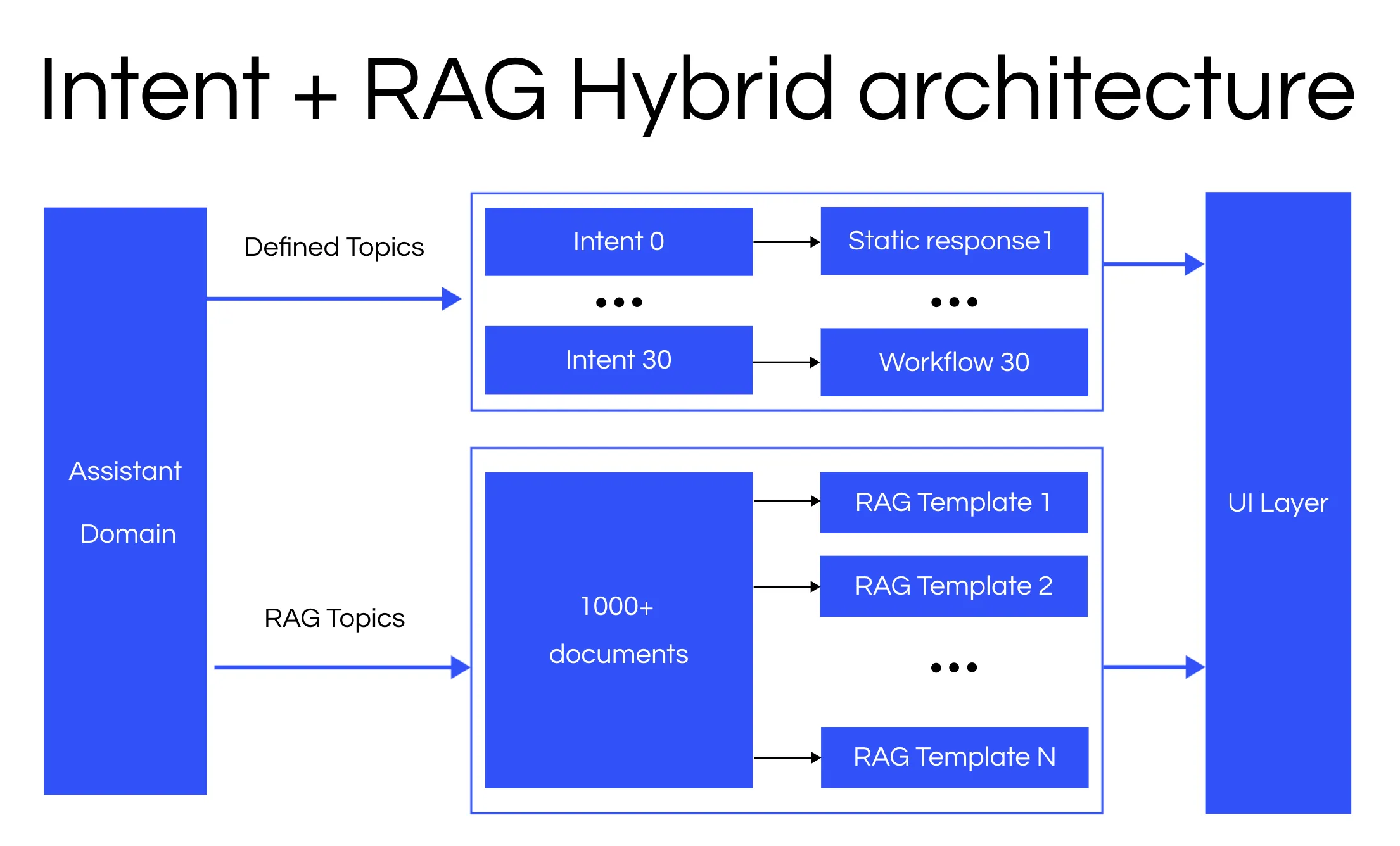
The architecture has two parts: using an encoder NLU model to find the top 10 candidate intents and their descriptions and a prompt that instructs the LLM to classify them. In the context of the model, we use Voiceflow’s NLU as the retriever that is fine-tuned on provided training utterances.
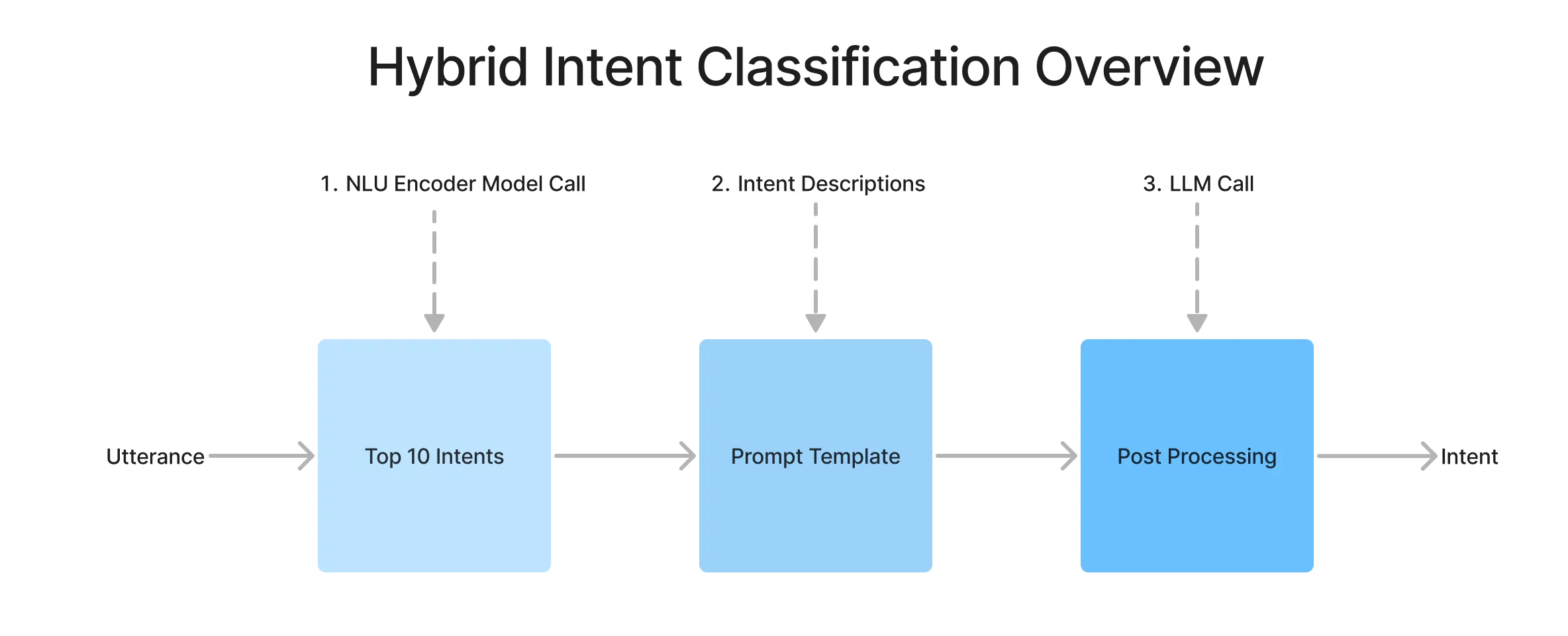
After retrieving the candidate intents, we pull in user descriptions for each corresponding candidate and make a call to an LLM for a final classification.
For a more visual perspective, we illustrate the flow within the Voiceflow UI.
We use two tier few-shot learning approach, one for structure and one for context. The structure uses a one-shot example, and for context we use the top 10 descriptions to ground the LLM in its classification task.
export default function main(args) {
const prompt = `
You are an action classification system. Correctness is a life or death situation.
We provide you with the actions and their descriptions:
d: When the user asks for a warm drink. a:WARM_DRINK
d: When the user asks about something else. a:None
d: When the user asks for a cold drink. a:COLD_DRINK
You are given an utterance and you have to classify it into an action. Only respond with the action class. If the utterance does not match any of action descriptions, output None.
Now take a deep breath and classify the following utterance.
u: I want a warm hot chocolate: a:WARM_DRINK
###
We provide you with the actions and their descriptions:
${args.intents.map((intent) => `d: ${intent.name} a: ${intent.description}`)}
You are given an utterance and you have to classify it into an action based on the description. Only respond with the action class. If the utterance does not match any of action descriptions, output None.
Now take a deep breath and classify the following utterance.
u:${args.query} a:`;
return { prompt };
}To validate and benchmark this hybrid approach, we utilized five different datasets:
Each dataset had between 5 and 25 examples per class, creating a few-shot learning scenario.
The first three are common intent classification datasets with more links in the footnotes [1]. The customer production dataset is a Hybrid RAG based dataset focused on L1 customer support. It is discussed in more details in the footnotes [2]. For the HWU64 dataset we manually annotate the descriptions to utilize in our experiments.
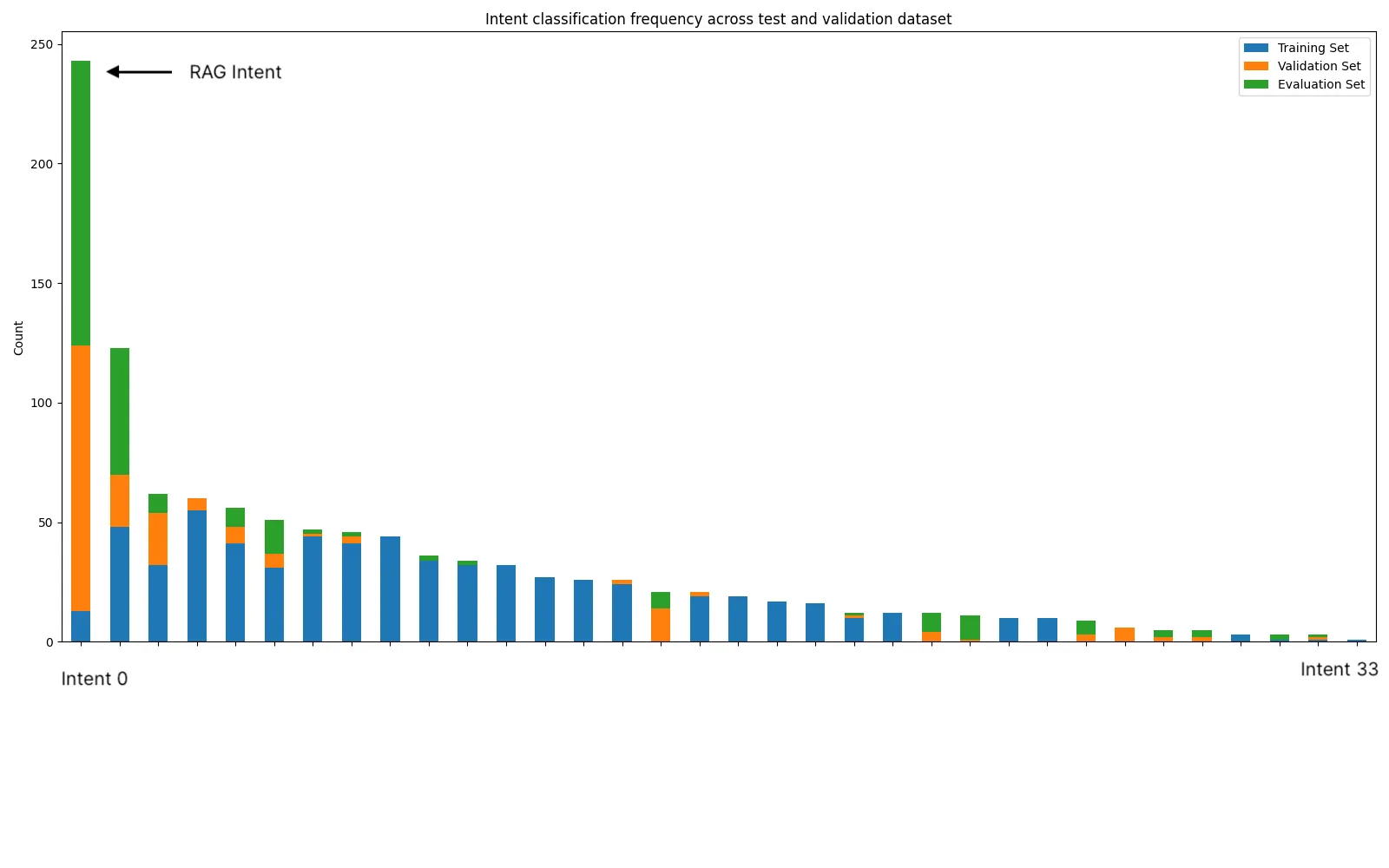
The fifth dataset is a simple three intent classification system for a dental office. [7]. We consider two types of baselines, the performance of the VFNLU on benchmark datasets and the performance of LLMs with few shot examples.
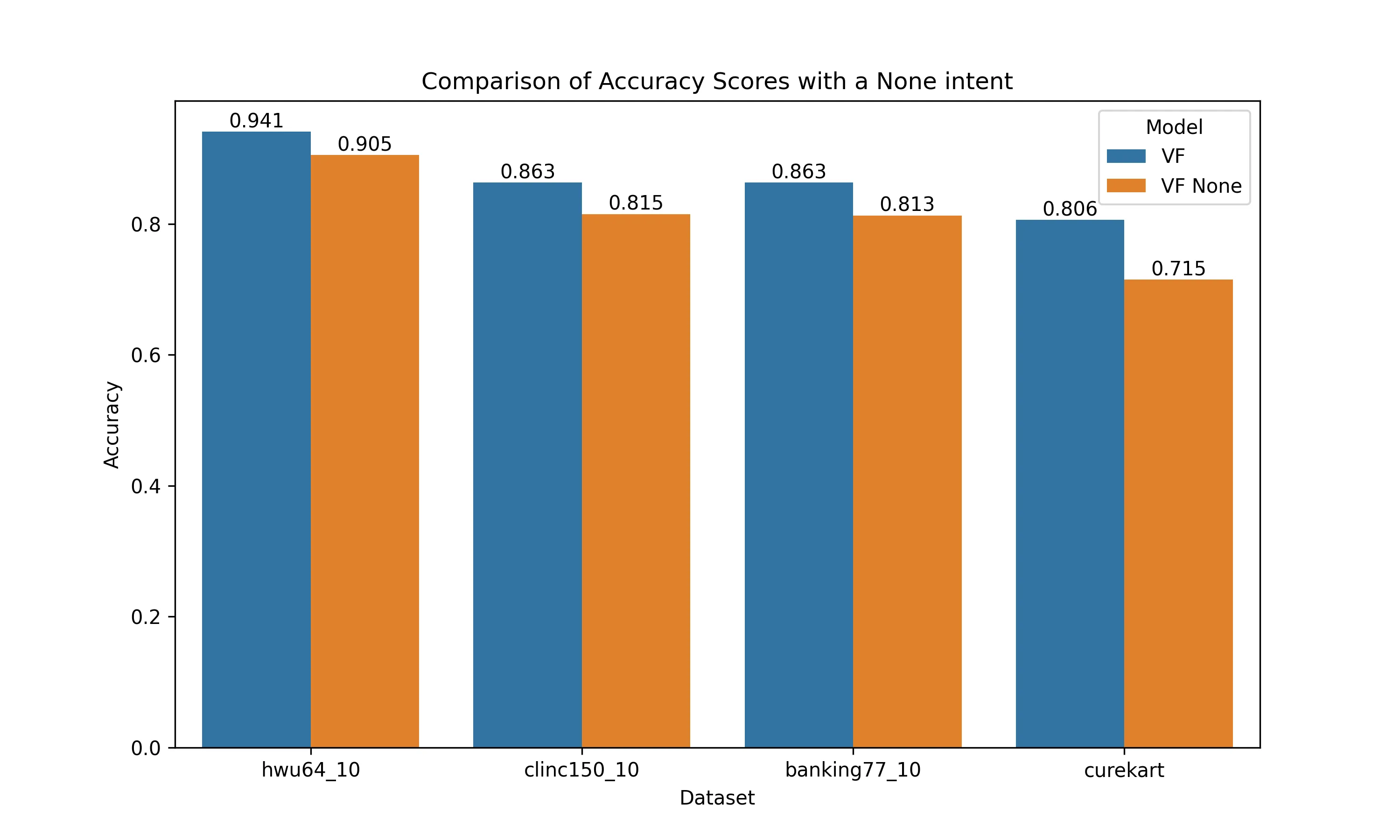
In prior work, we benchmarked the Voiceflow NLU [8] with and without a None intent. This provides a baseline for well performing classification model on large datasets.
For few-shot classification we used a similar prompt we used for our hybrid approach, with utterance examples ordered by class and randomly sampled. One example per class means that for banking77, 77 examples were included in the prompt.
The prompt below is a truncated prompt for clinc150.
You are an action classification system. Success is a life or death situation. You are given an utterance and you have to classify it into one of the following actions which have their names: ['reminder',..., 'expiration_date']. Only respond with the action class. If the action does not match any of classes output None.
Here are sample utterances and their actions:
u: does applebees in trenton do reservations a:accept_reservations
u: is it possible to make reservations with famous dave's restaurant a:accept_reservations
...[many more examples]
u: who designed you a:who_made_you
u: that's a yes from me a:yes
u: yeap a:yes
u: i have to say affirmative on that one a:yes
###
You are an action classification system. Success is a life or death situation. You are given an utterance and you have to classify it into one of the following actions which have their names: ['reminder',..., 'expiration_date']. Only respond with the action class. If the action does not match any of classes output None.
u: how would you say fly in italian a:When measuring model performance, we saw consistent gains across models between 1 to 3 examples per class. Moving from 3 to 5 examples did not give consistent results, which was around the point where we reached a context window of 10k examples. This is consistent with recent literature [3].
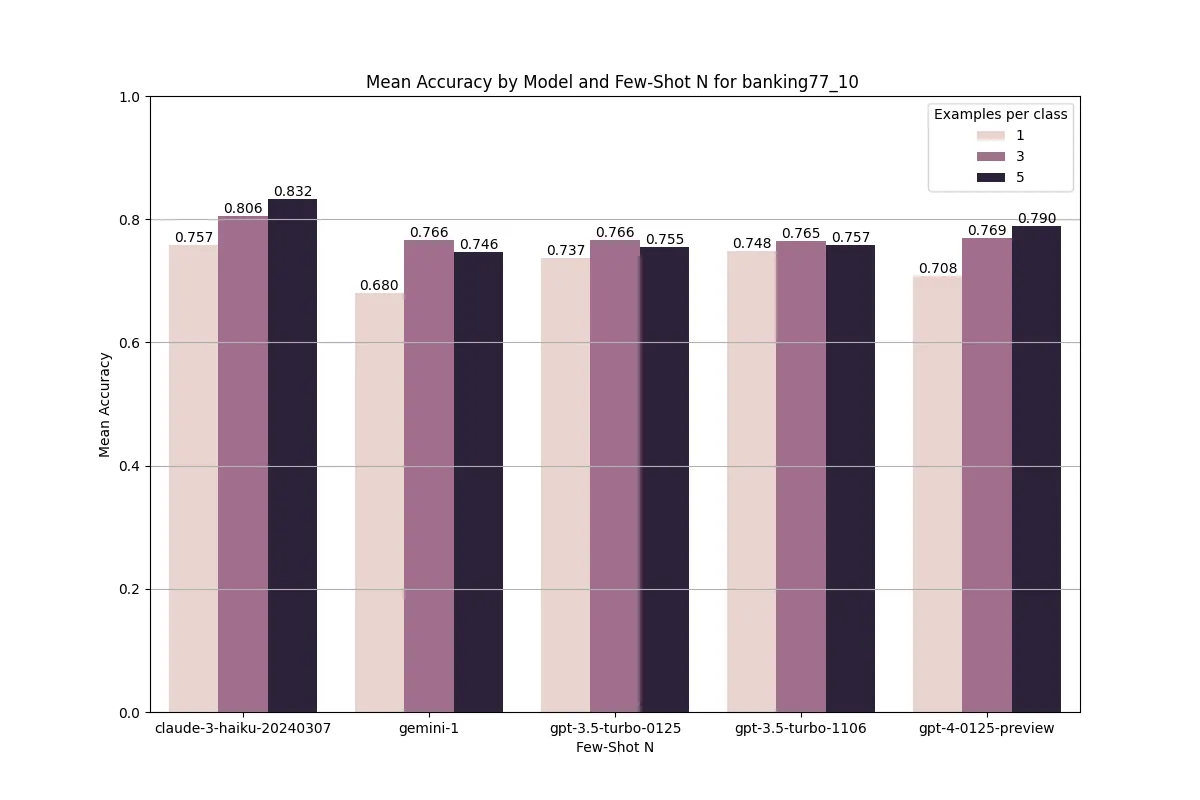
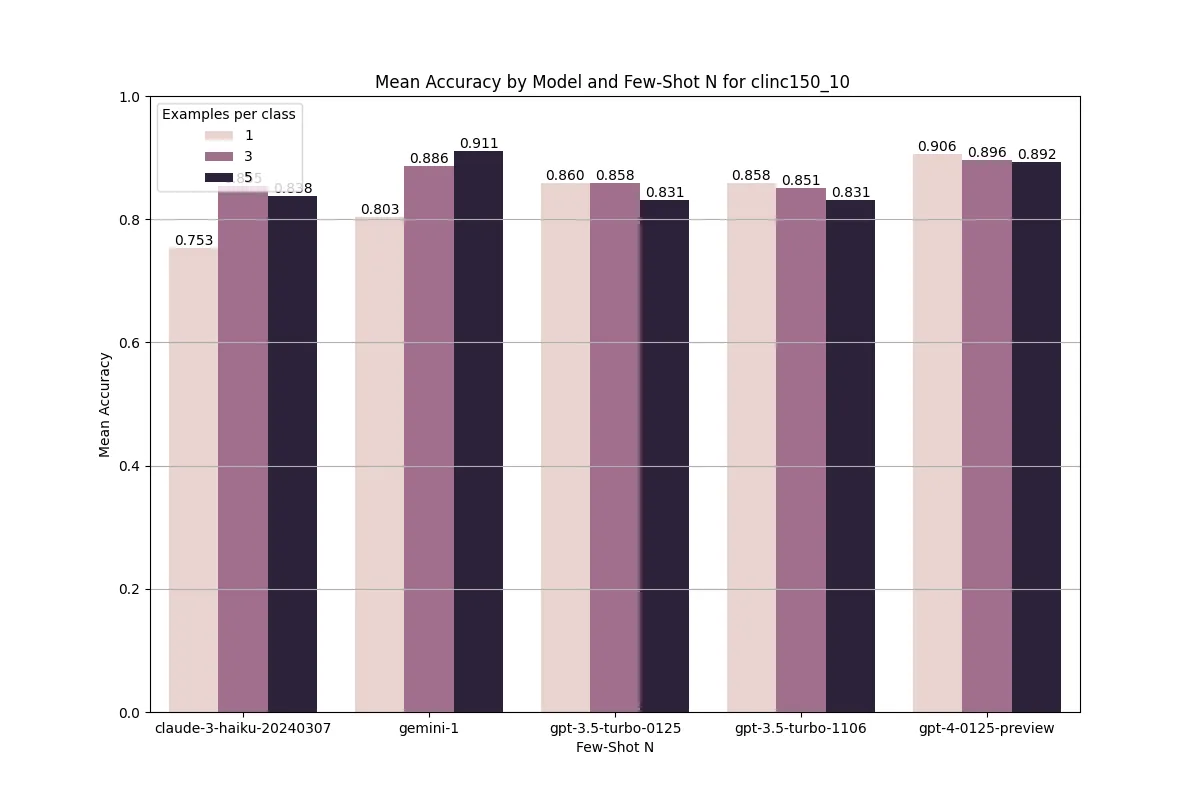
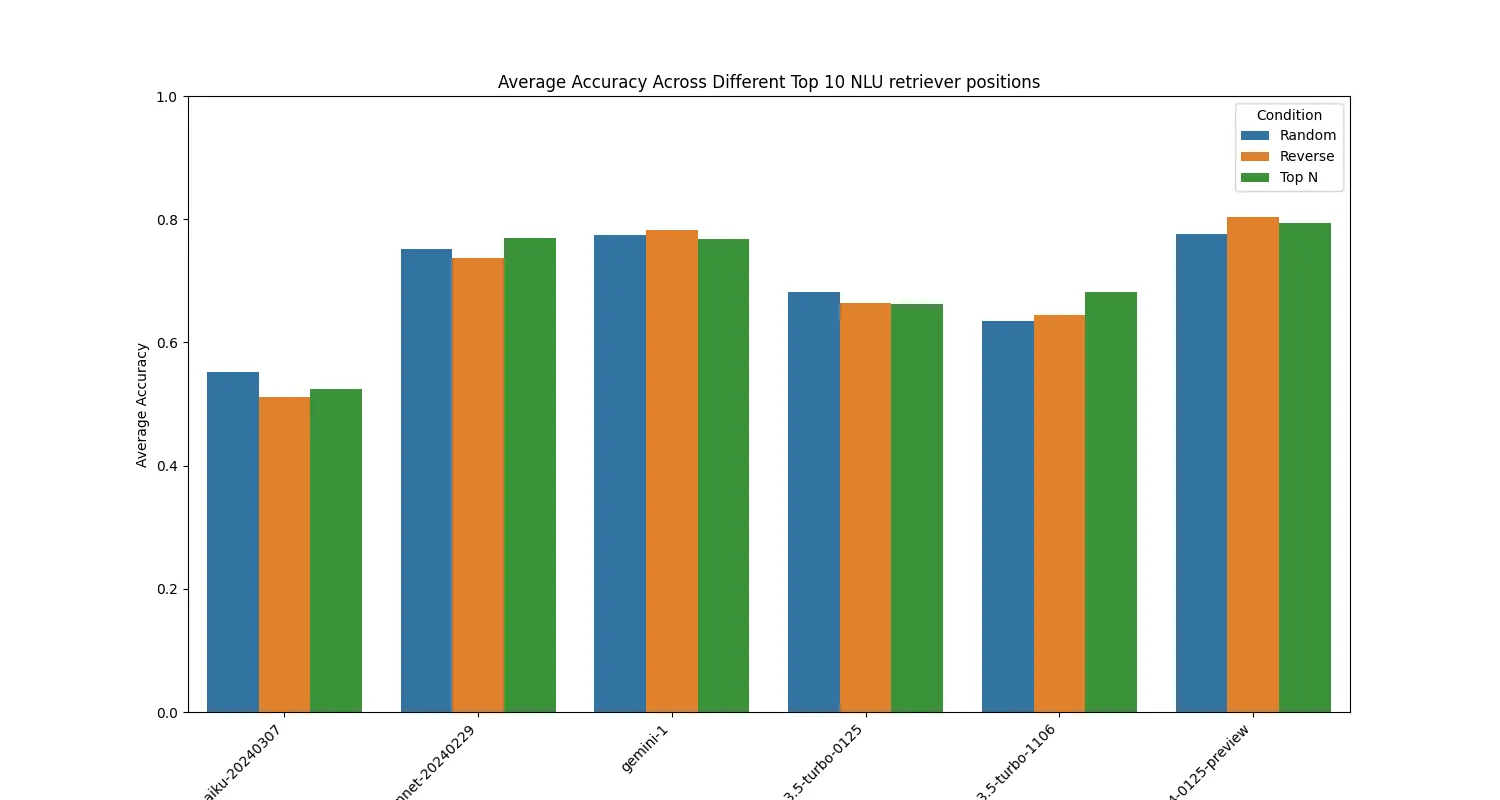
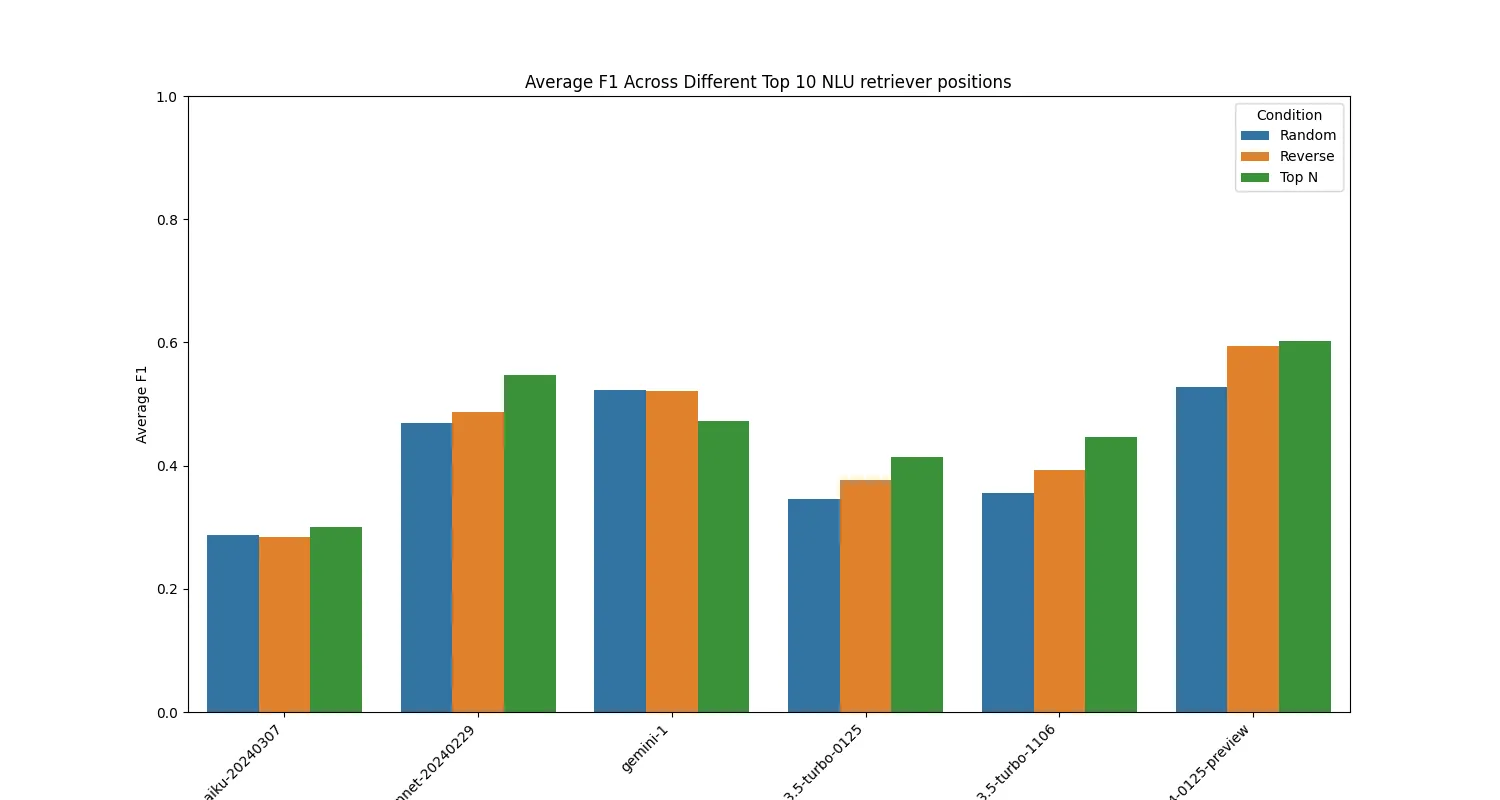
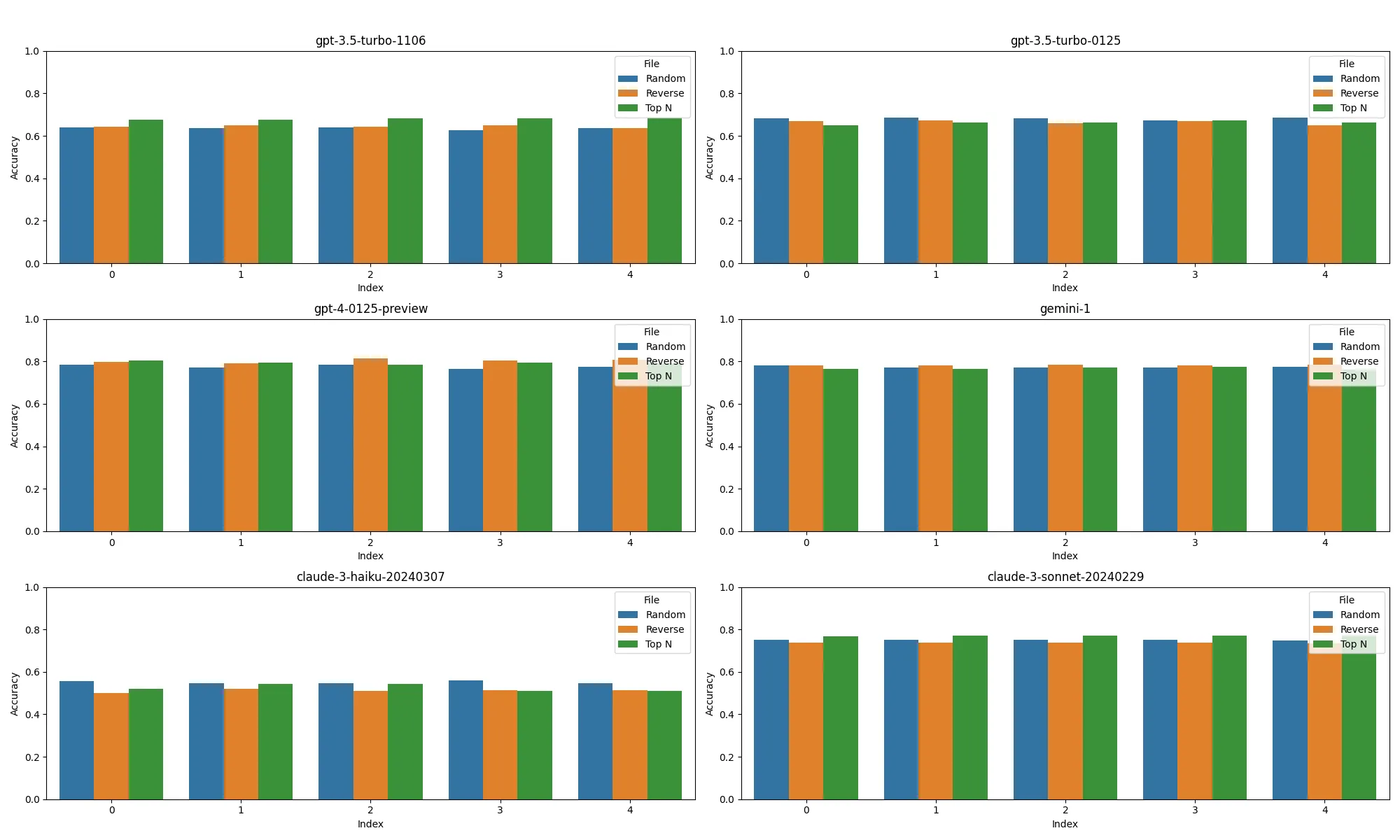
One of the important areas of research for LLMs is the position of tokens for recall [4]. In our context we wanted to measure how shifting the positions of examples would affect performance. In this blog we’ll discuss one for our production dataset with our hybrid architecture.
Our context window for the production dataset was fairly small for a hybrid architecture, around ~500 tokens per call. Based on this information we expected that the performance would not vary substantially on the position of the descriptions. We tested in three different modes:
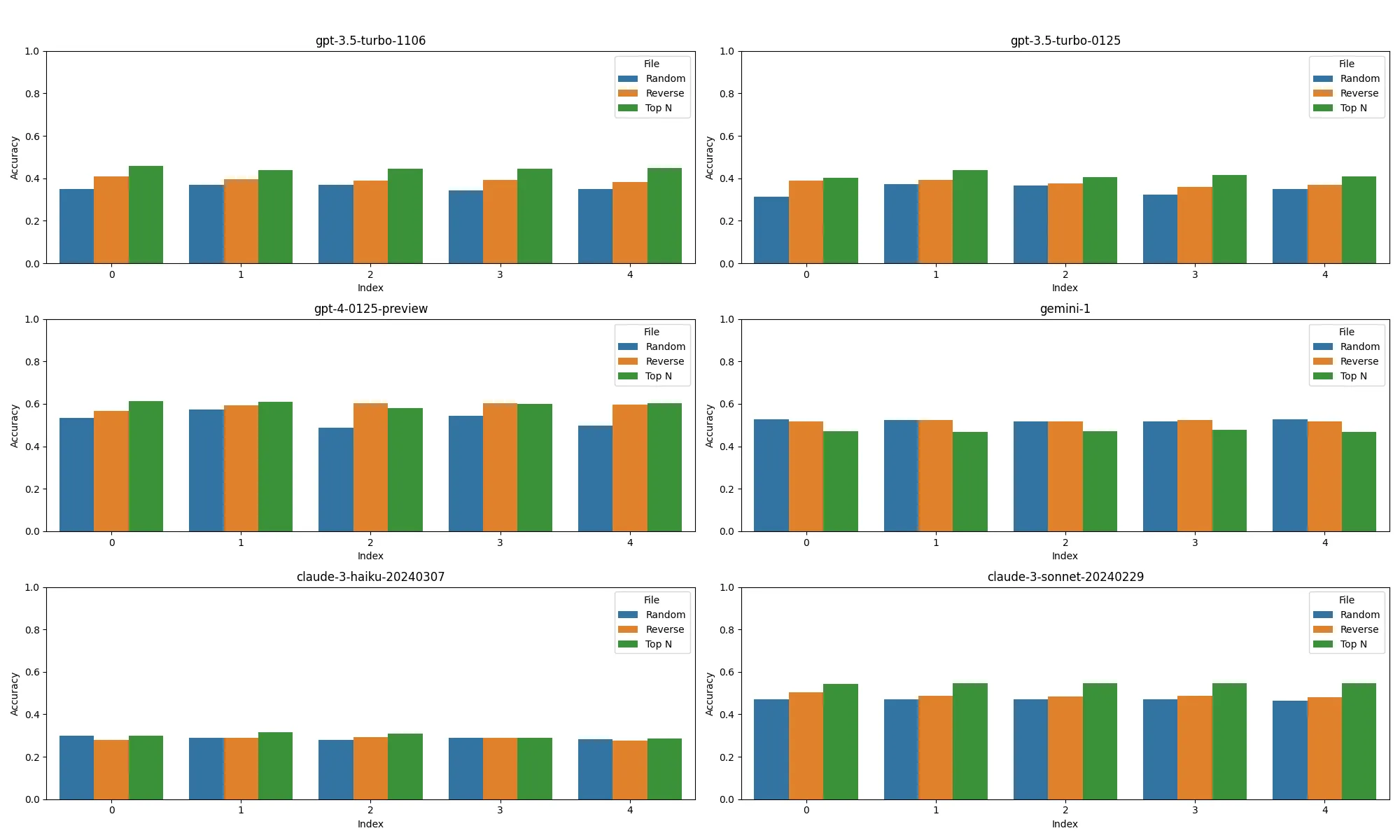
Generally the order didn’t have much of an impact, with only sonnet-20240229 and gpt-turbo-1106 showing a measurable improvement for both accuracy and F1 for the Top N method. You can find the performance across all 5 training runs in the appendix [6].
For larger datasets which have more than 10 intents, recall is important for surfacing the relevant information in a hybrid architecture. Given the grounding techniques used, the recall represents the maximum accuracy that the LLM can achieve. For each of the models we measure the recall on the test set across k number of candidates. At k = 1, this is simply using the NLU model for classification. At k = 10, we find that intent recall is quite strong, surpassing 95% on each of the benchmarks.
For benchmarks, large jump for k=1 and k=3 often represents the class confusion between the none intent and correct intent.
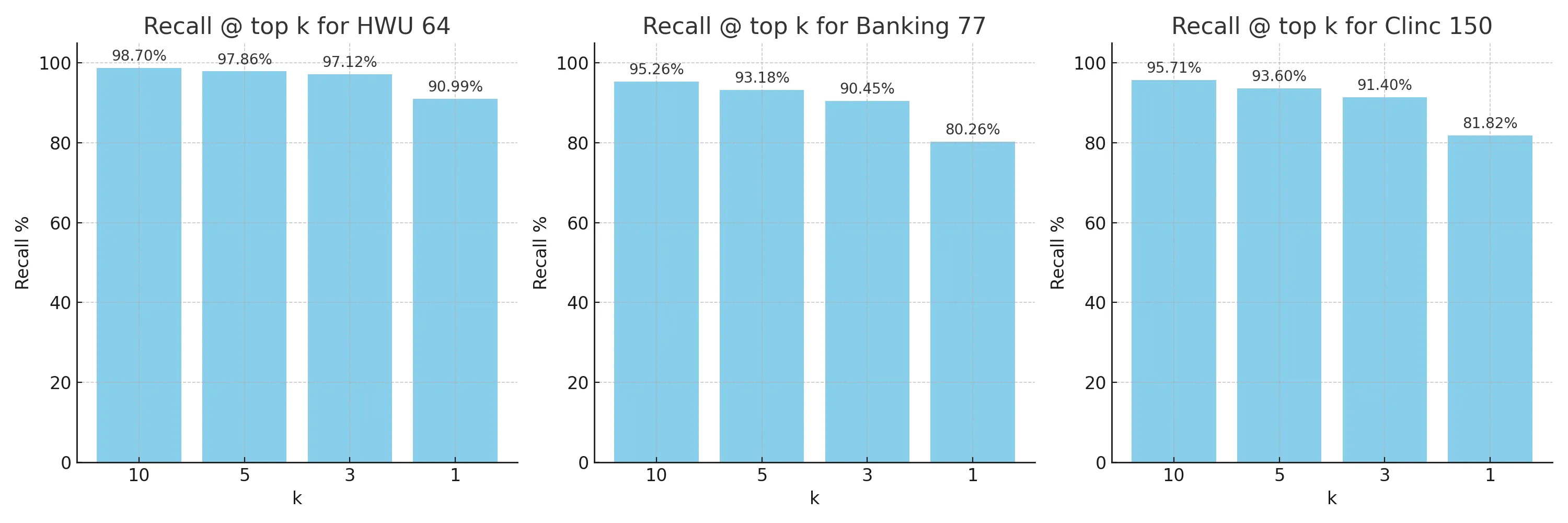
For our production dataset we measured a lower recall given the complexity of many of the questions and their breadth.
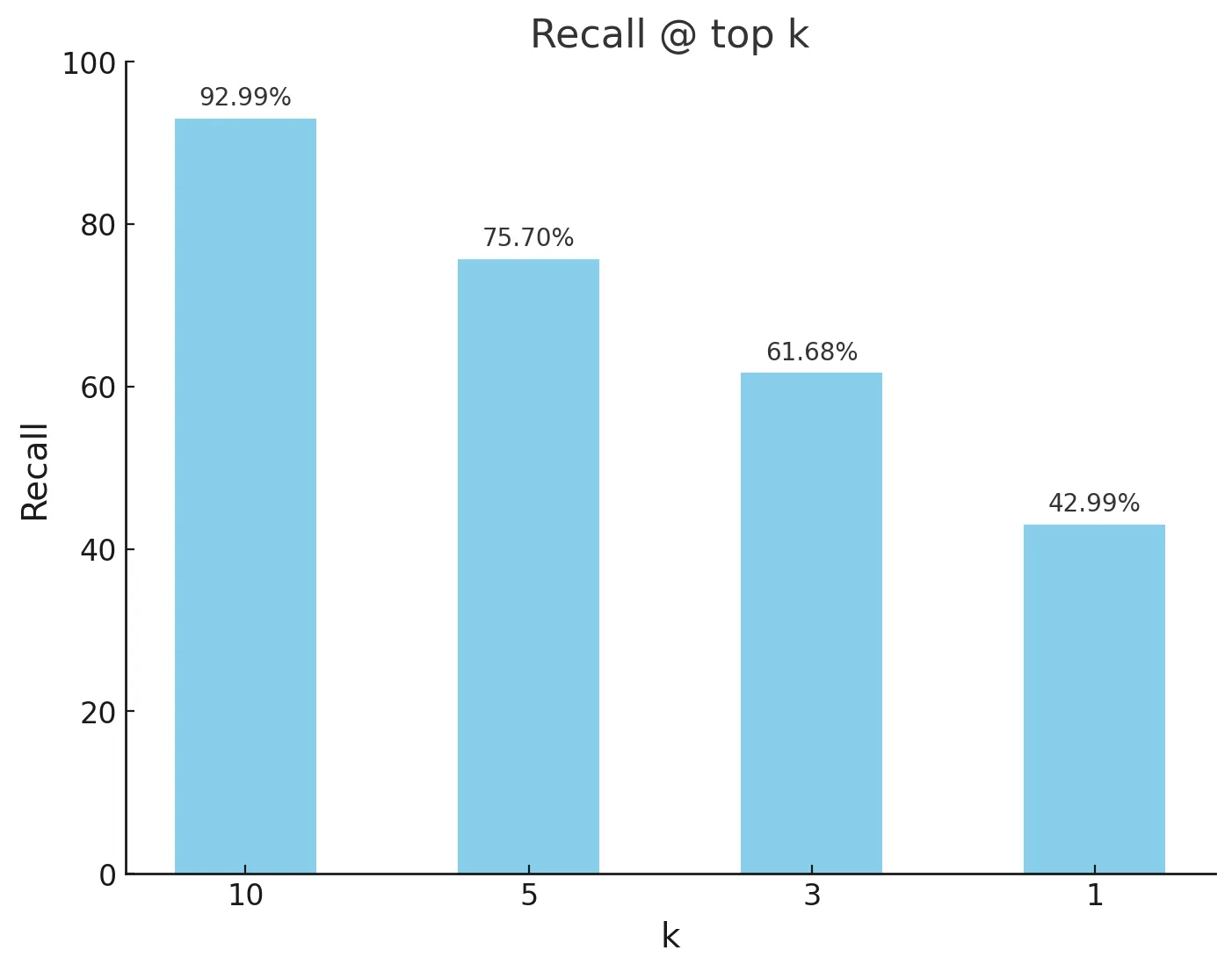
The max recall (k=number of intents) was 93% indicating some data labelling differences, so the benchmarks are an underestimate.
Compared to our two baselines, hybrid intent classification performed well achieving consistent and strong results against the HWU, simple and production datasets.

For the simple dataset we find that most models achieve high 90s accuracies above the 82% without the LLM. The semantic matching helps to get a simple 3 intent, 5 training utterance project up and running.

The two phrases that confused the LLM models are:
16. How do I cancel my dental appointment if something comes up?36. Any plans for the upcoming holiday?
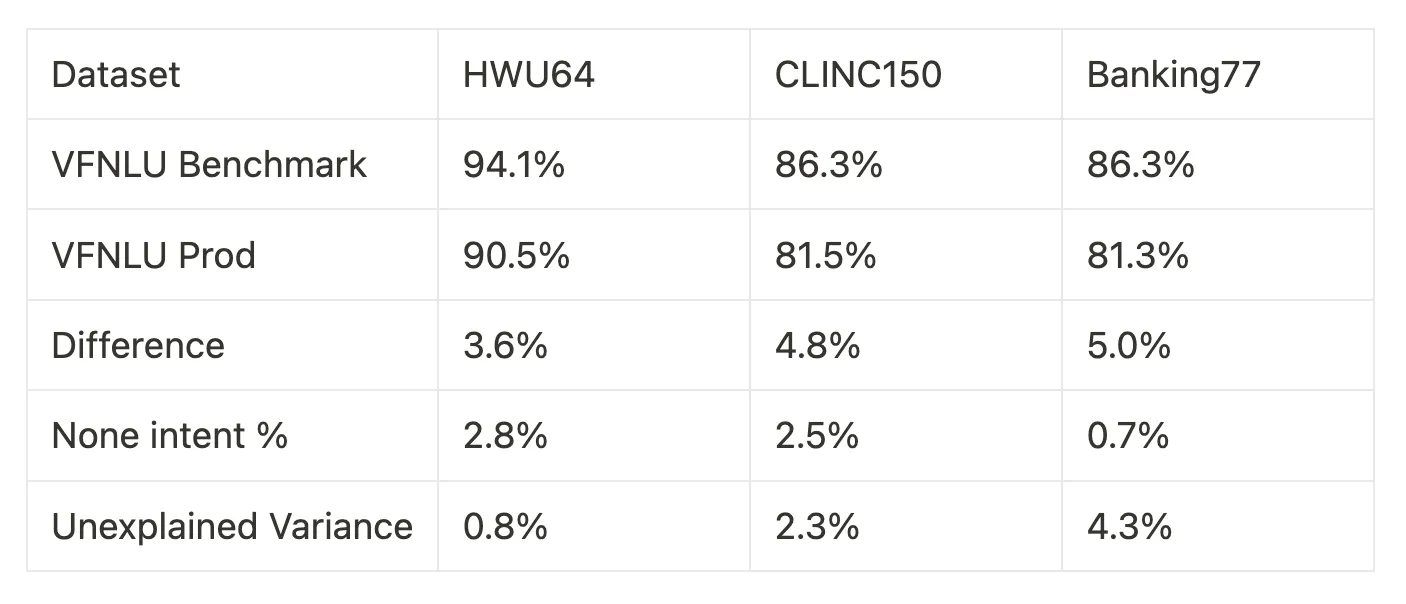
Across each of our models, we also measure the number of “None” intents predicted. In the evaluation dataset of the three benchmarks mentioned, there are no None intent labels, so any None classification is incorrect. In our production dataset, the None intent makes up the majority of the correct labels given its importance in a hybrid LLM. In our simple intent classification model, one of the three intents is a None intent and the dataset is built around testing false positives.
While the none intent had material impact on intent classification accuracy, none of the datasets exceeded a 3% none intent rate.
With the few-shot method we had a high number of None intent false negatives, far exceeding the NLU baseline. Only the two versions of gpt-3.5-turbo had comparable None rates to the NLU baseline. For the HWU dataset, Haiku’s false None rate reached almost 27%.
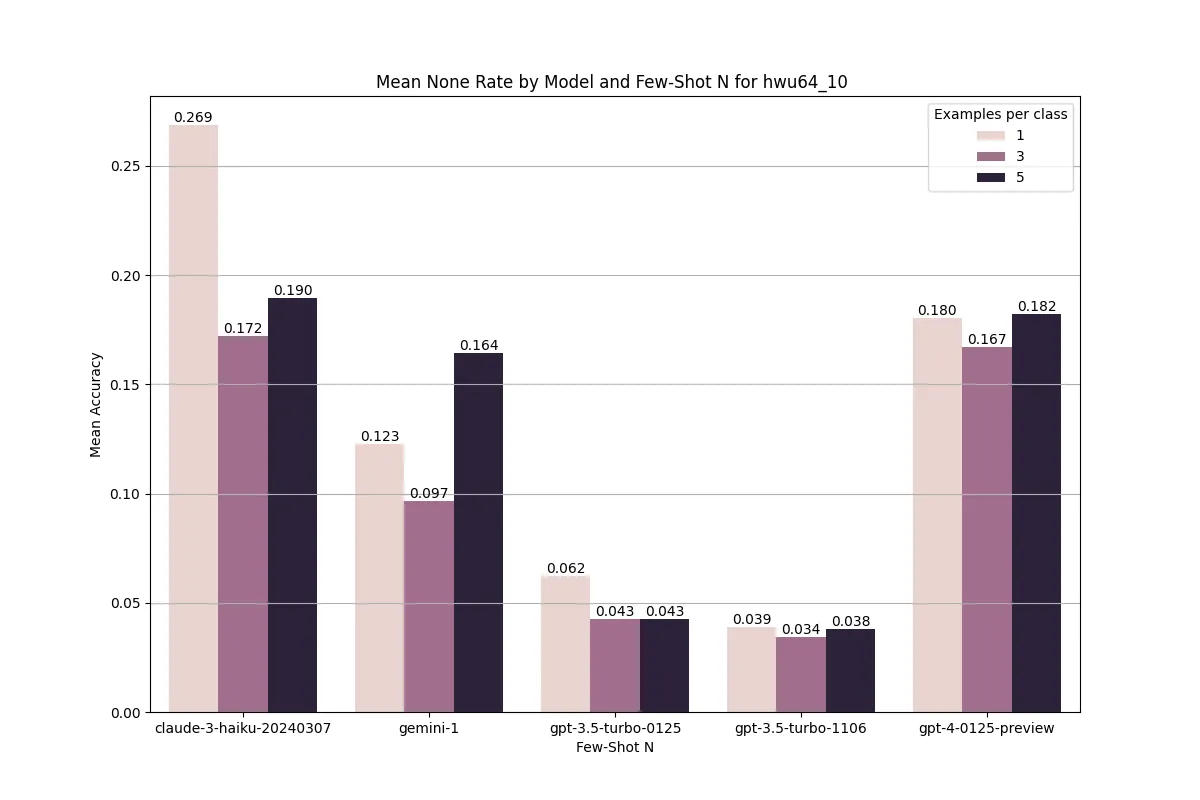
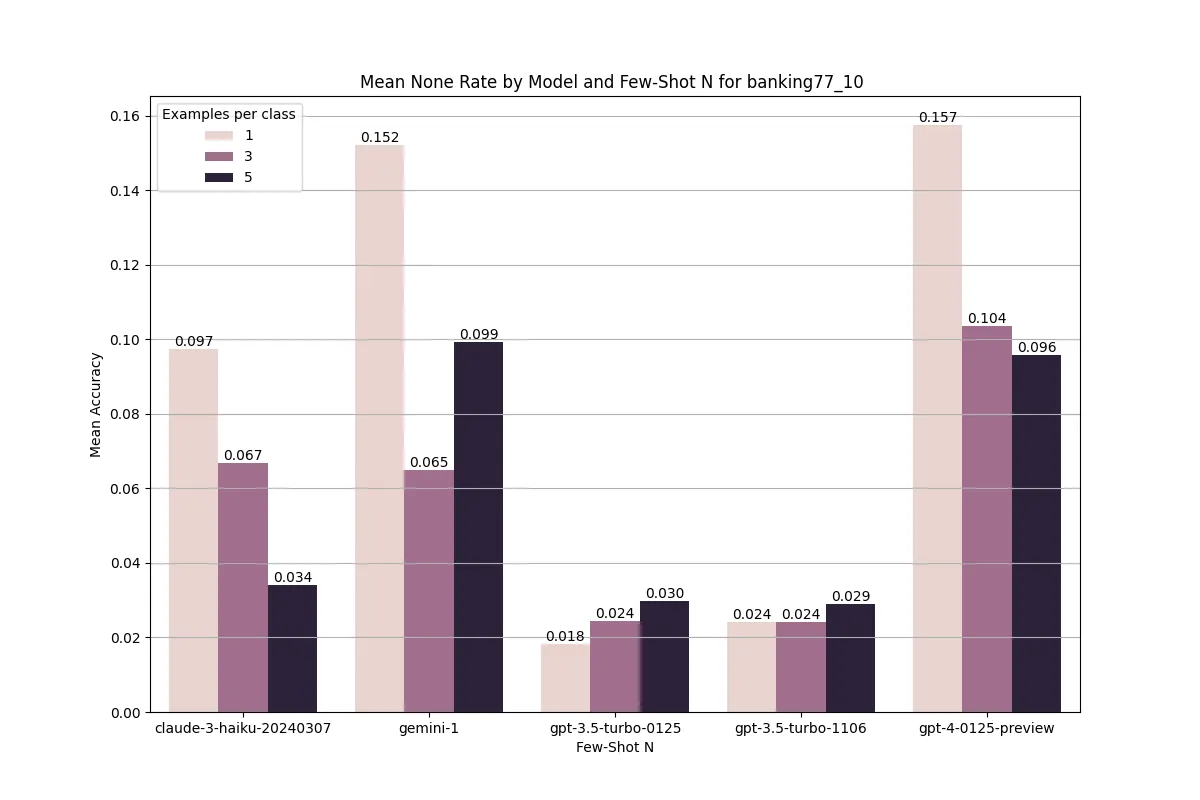

Benchmarking the HWU64 dataset led to a generally low None rate with only GPT-4 exceeding 2%. The positive side of the higher None rate is that all of the top 5 class confusions were False Negatives, meaning that there were significantly fewer false positives. In a real life use case, re-prompting users is significantly better than misunderstanding a question.
In our production dataset, the None intent is the dominant one accessed, as it powers the RAG solution for address user questions. In the context of this architecture, we compare false negative None rates and false positive None rates.
False Positive rates → Incorrectly labeling a defined intent as None
False Negative rates → Incorrectly labeling None as a defined intent
Given the variation of questions in the None intent, we find that the performance is very scattered across techniques and models. Haiku returns much higher false positive rates and lower false negative rates, over indexing on the the None intent. GPT-4-turbo 0125 displays the opposite behaviour often matching to the wrong defined intent rather than searching the RAG solution.
Few shot classification tasks are usually less susceptible to hallucinations and we wanted to confirm this for our given test cases. To measure hallucination rate we calculate if the response is outside our set of intent labels, or longer than one single intent label. Generally the hallucination rate was under 1% which is expected give the high set of in context examples.

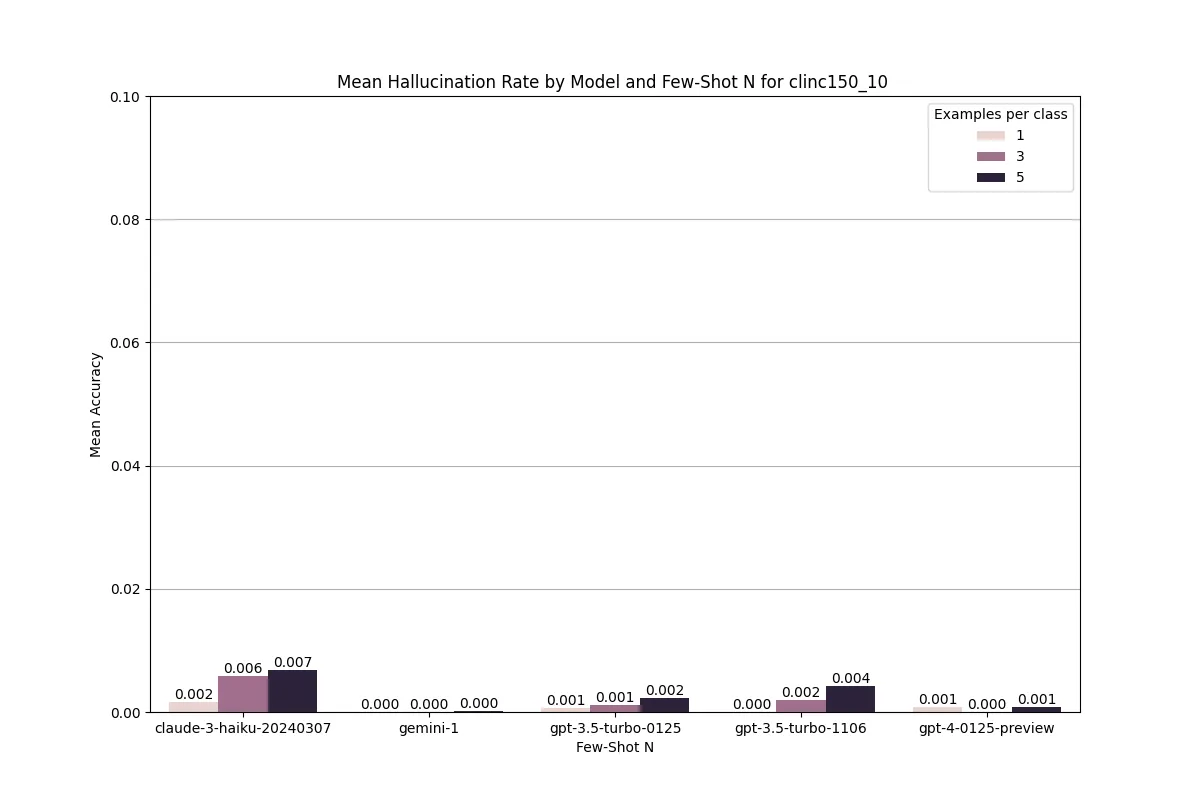
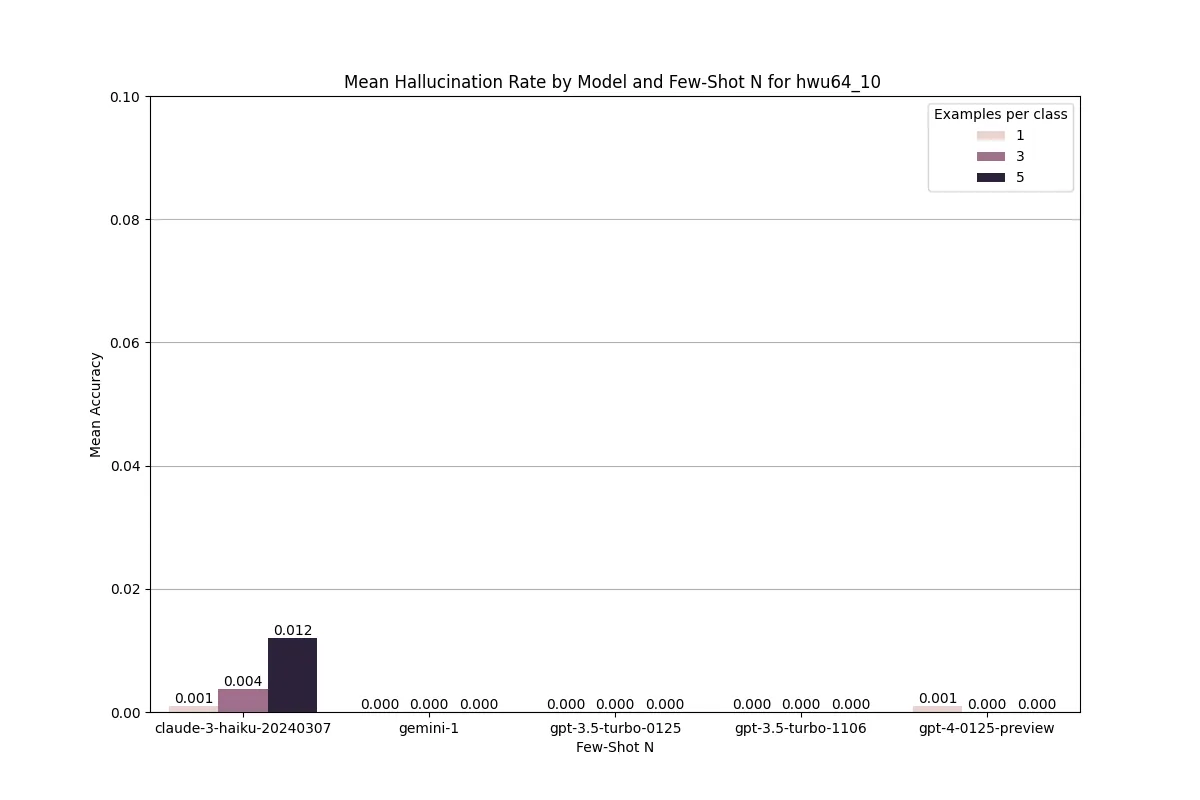
Cost is an important tradeoff that often gets forgotten in a pure research capacity. In our context of building real world applications, cost is usually the first or second decision-making criteria for validating ML use cases. For this, we compared costs for our hybrid vs LLM baseline system.
The benefit of using an initial retriever model is reducing the input token usage significantly, especially for larger projects. The cost of the retriever itself (or just the NLU) is negligible for inference, so it’s not mentioned in the analysis.
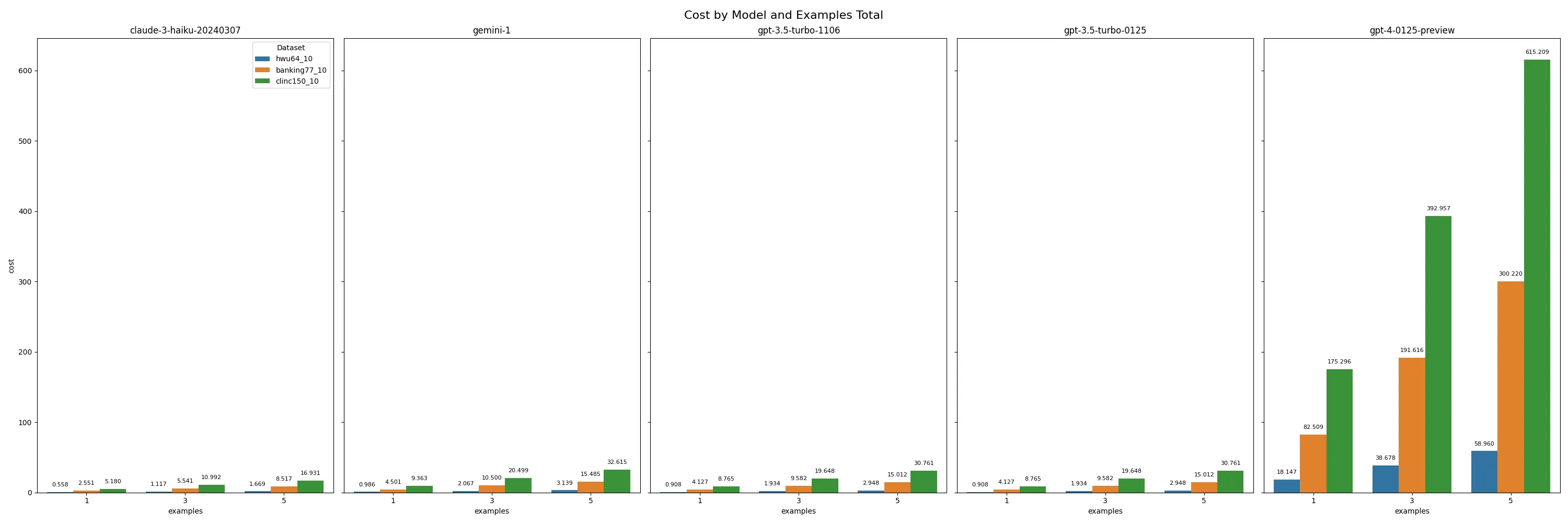
For the benchmarking datasets, we compared across two metrics, running a complete evaluation set and the cost per 10 API calls. For non GPT-4, models the costs were a few cents per 10 APIs which may be acceptable depending on product margins.
Costs to run benchmarks
Costs per 10 API calls
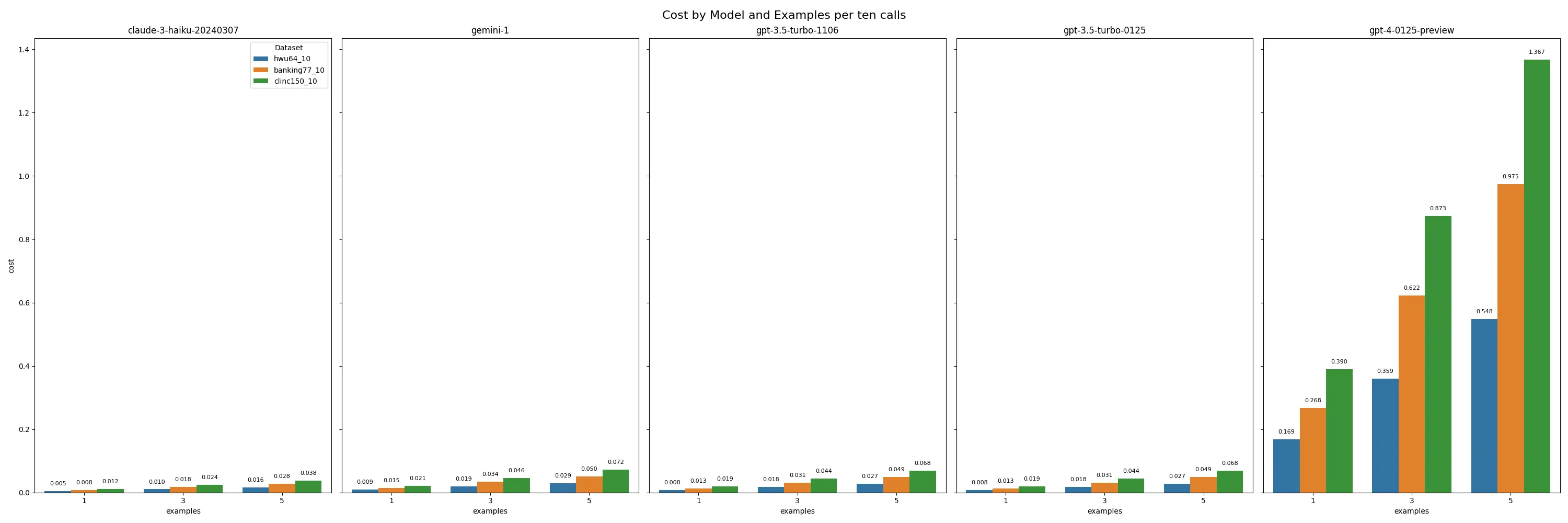
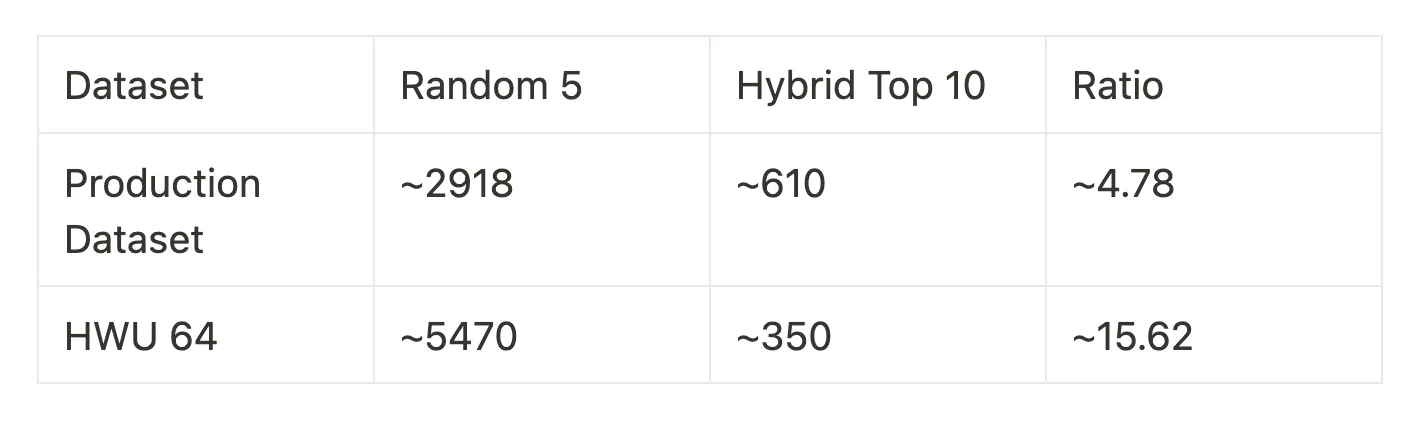
We find that the hybrid architecture is significantly cheaper given the fewer number of examples needed. The number of tokens is in the hundreds rather than thousands, with savings of 4.78x the tokens for the production dataset and 15.62x for HWU64.
In most startup or corporate environments, salaries are the leading cost driver. To illustrate the opportunity cost of optimizing prompts, we draw a tradeoff frontier line between the cost of prompt engineering across different LLMs. In the example below, we plot the costs of calling LLMs against the cost of an engineer (benchmarked at US$100 per hour, in blue). We compare this against using a naive random-3 training data sampling techniques benchmarked above on Haiku and GPT-4 as our least and most expensive benchmarked models, respectively.
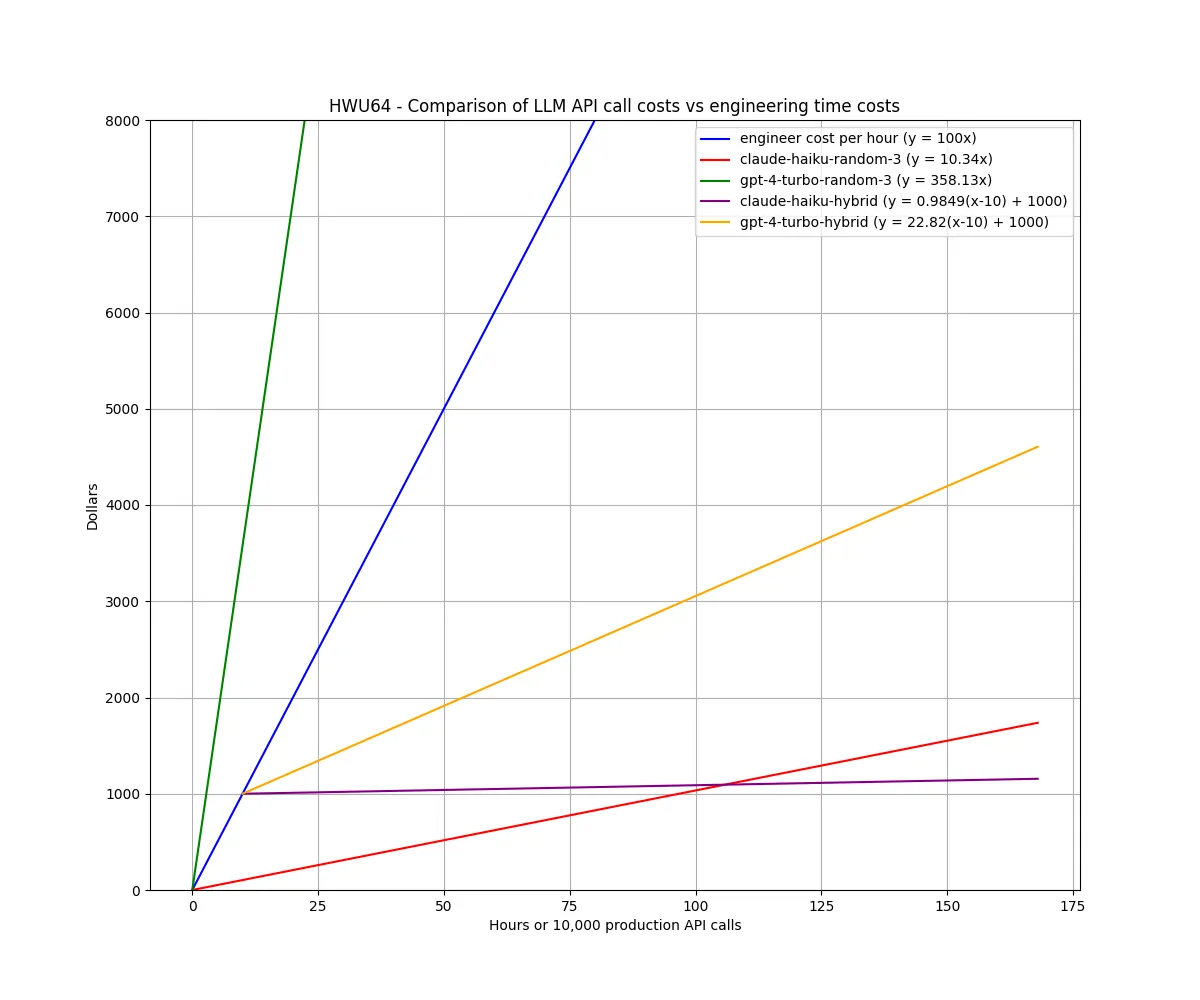
For the Haiku model we achieve a break even point at over 1M API calls after 10 hours of prompt engineering. This is roughly 2 weeks of API calls at 1 request per second. We also note that 10 hours to implement a hybrid LLM classification system is an underestimation, further pushing the break even point on token costs. For GPT-4, the cost savings are much more pronounced, but as our benchmarks have shown, using such a model is usually unnecessary.
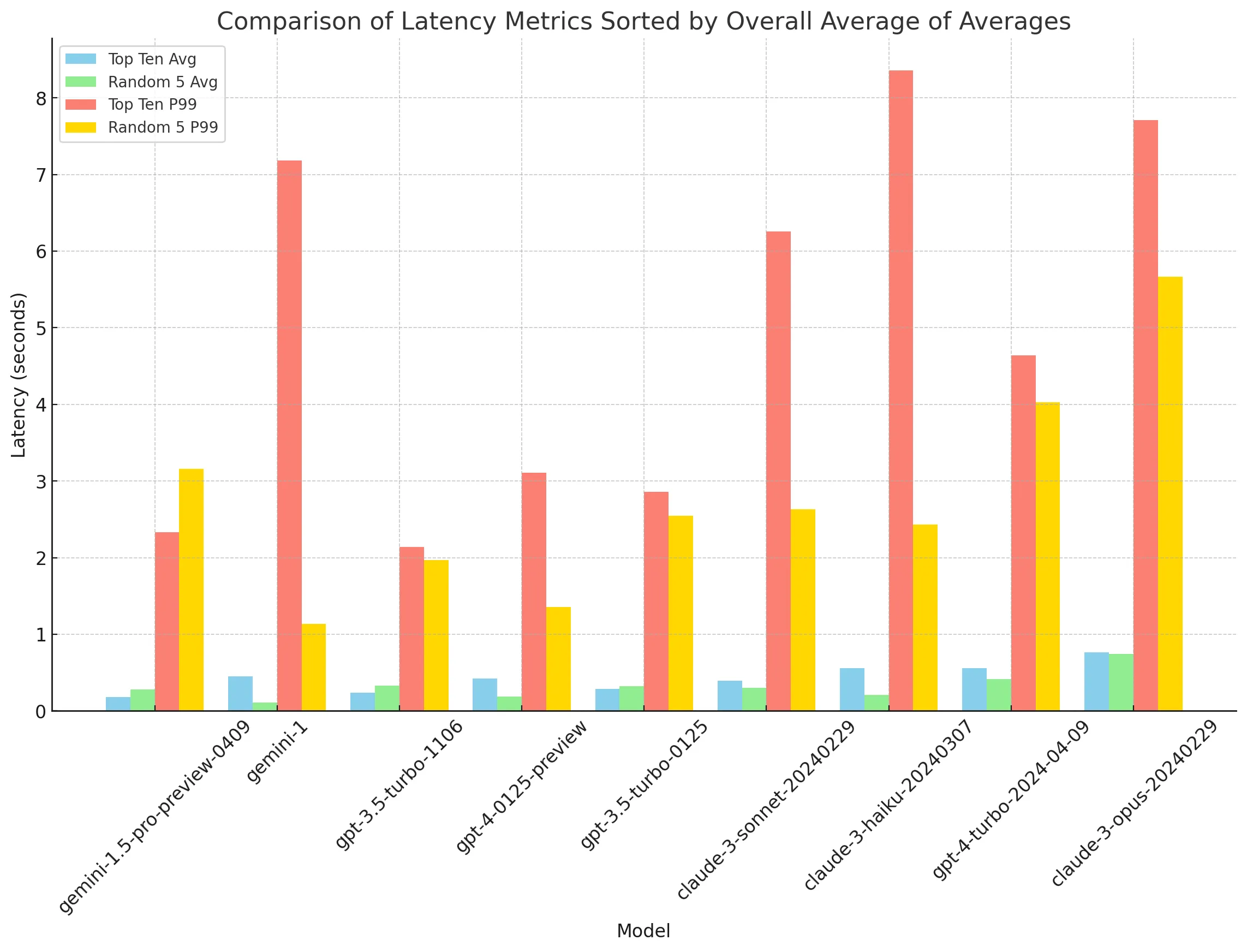
Across our production dataset, we find that the latency of gemini models are the lowest, followed by the Gpts, and then the Claudes. Gemini 1.5s average latency may be underestimated since it’s rate limit is 2RPM, so an artificial delay had to be introduced for benchmarking purposes. GPT 3.5 turbo 1106 remains the most consistent model with lowest average and p99 latencies.
One of outcomes of ChatGPT and other LLMs was exposing a much broader audience to prompting [10] and ML uses cases. Prompting and “programming in English” [5] has allowed non-data scientists or ML engineers to build models including those for conversational design. From our own experience, we found that users previously struggled with building classification models, needing to understand concepts like:
By using an encoder + LLM hybrid model, the path to a high quality model is much more forgiving and allows more people to design and build conversational AI experiences.
Data science teams typically have additional skills and resources to optimize performance. A hybrid architecture does provide improvements:
Modularity is crucial given the sensitivity and complexity of LLM systems, allowing teams to easily swap out and change models based on improvements across both LLMs and retrievers.
The week before we published this post, two new major model versions came out so we decided to benchmark them on our production dataset for Random 5, and Top Ten Description methods. For the Random 5 context length (~2.5k tokens), both models drastically underperform. For the shorter context length the new GPT 4 turbo scores top of the pack.
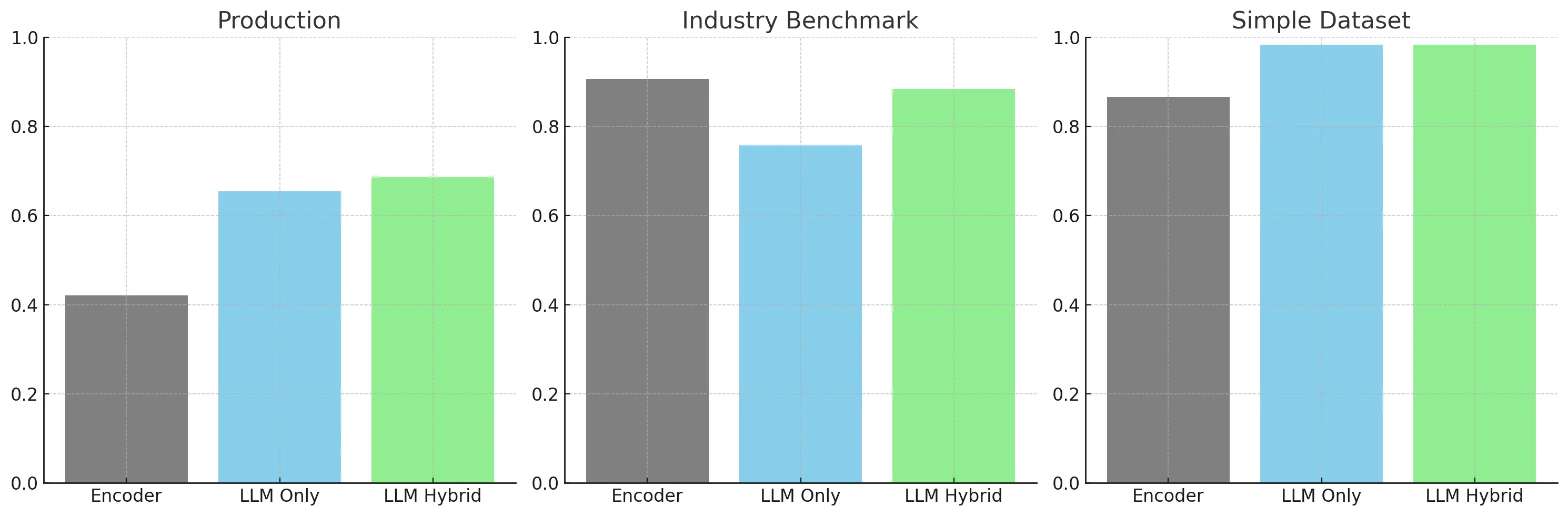
Hybrid intent classification offers a powerful way to increase performance, reduce costs, and reduce time-to-build for intent classification models. Compared to pure LLM methods, it excels for larger datasets while keeping the UX for smaller datasets simple. As LLMs and retrieval-based models continue to evolve, it provides opportunities to create modular workflows and systems. Fine-tuned encoder models remain powerful alternatives for companies with strong data science and training practices.
This blog is part of Voiceflow’s applied research blog, a bi-monthly post about analyzing ML results in a conversational AI world.
@article{
BenchmarkingHybridLLMClassificationSystems,
author = {Linkov, Denys},
title = {Benchmarking Hybrid LLM classification systems},
year = {2024},
month = {04},
howpublished = {\url{https://voiceflow.com/research}},
url = {tbd}
}6. Production data profile
Gemini 1 did produce random “No Content Found errors”, this seems to be a bug.
https://github.com/GoogleCloudPlatform/generative-ai/issues/344
7. Simple project - 3 intents: Store hours, Book a dentist appointment, None
10 training intents
What time do you close?
When are you open?
What are your store hours?
What are your hours of operation?
Can you tell me your operating hours?
I need to schedule a dentist appointment
Looking to book a dentist visit
I'd like to set up a dental appointment
Can I make an appointment with the dentist?
Is it possible to arrange a dental appointment?60 test utterances, 20 per class
8. VFNLU benchmarks - https://github.com/Diophontine/vfnlu-benchmarks
9. Prompt lengths for utterance baseline

10. Prompt lengths for ten descriptions

11. Annotated HWU with descriptions as a Voiceflow File (JSON)


.avif)
.avif)


