Voiceflow named a 2026 Best Software Award winner by G2
Read now

.webp)
Ticket deflection rate is the metric AI chatbot vendors lead with. It is easy to understand, easy to demo, and easy to inflate, which is exactly why enterprise support teams should treat it carefully.
A 70% deflection rate sounds impressive. It might also mean 70% of customers who contacted you never got their problem solved. Whether that number is good or bad depends entirely on what "deflected" actually means in a given deployment—and that definition varies more than most vendors acknowledge.
This guide covers what ticket deflection rate actually measures, what benchmarks are realistic for enterprise deployments, why deflection alone is a misleading success metric, and what to track instead if you want your AI support investment to compound over time.
Ticket deflection rate is the percentage of inbound support contacts that do not become tickets requiring human agent handling.
An interaction is typically counted as deflected when one of the following happens:
The problem with that last category is obvious once you name it. A customer who abandons a chat because the bot gave them a useless response has been "deflected" by most measurement conventions - even though their problem was not solved and they are likely to call back, email, leave a negative review, or churn.
This is why deflection rate, measured in isolation, is a metric that can be optimized in ways that actively harm your business. Vendors who report deflection rate without accompanying CSAT, resolution rate, or re-contact rate data are, at best, showing you an incomplete picture.
The metric you actually care about is not deflection. It is containment - and more specifically, successful containment. The percentage of interactions the AI agent resolved in a way the customer accepted as complete.
These three terms are used interchangeably by many vendors and should not be.
When a vendor quotes a deflection rate, ask which of these definitions they are using. When you benchmark your own deployment, track all three - because the gap between them tells you a lot about where your AI agent is succeeding and where it is failing customers while appearing to succeed on paper.
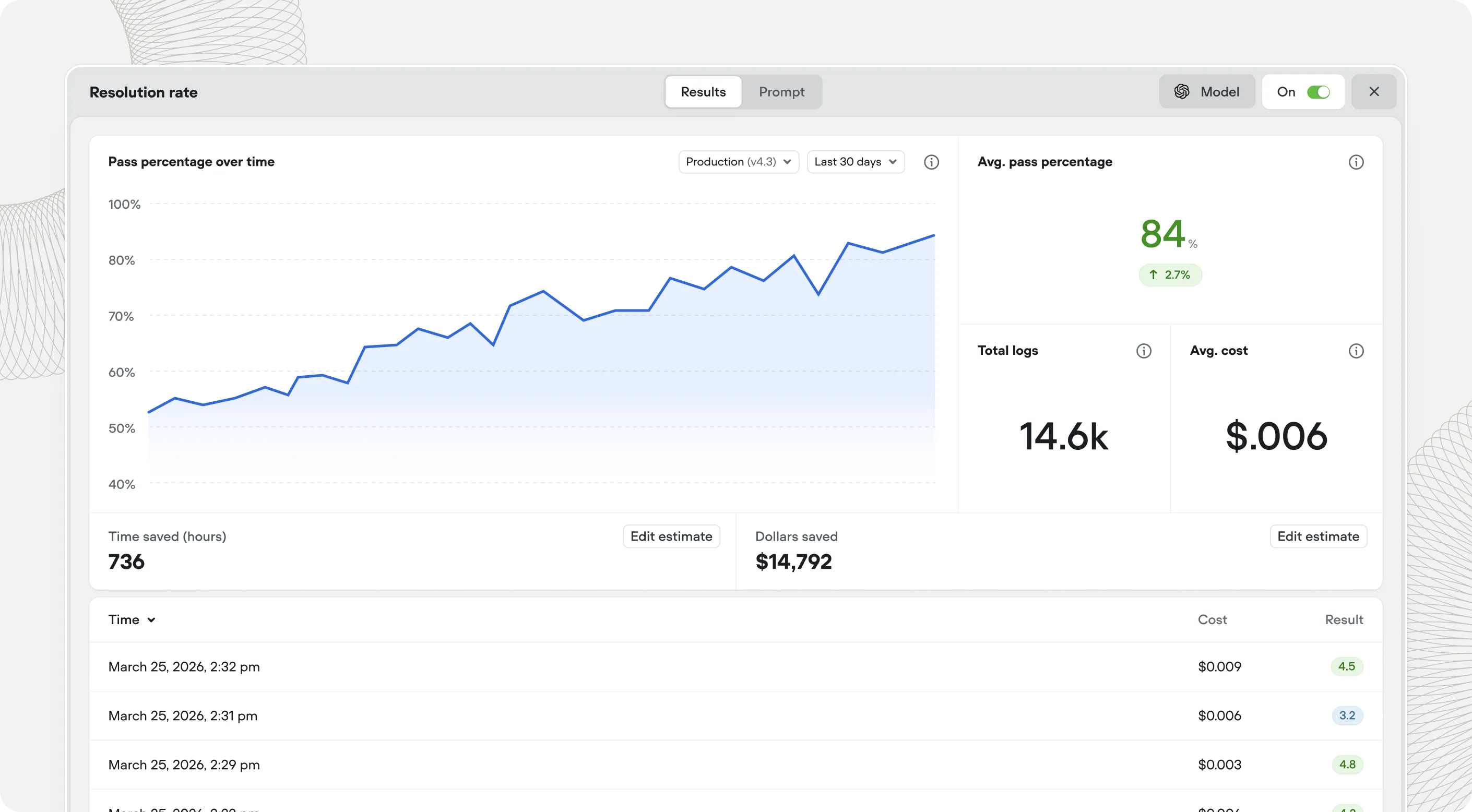
Benchmarks vary by industry, interaction complexity, and deployment maturity. Here is an honest picture based on patterns across enterprise deployments.
Containment rates of 70-90% are achievable within the first few months for interactions with clear resolution paths and good system integration. These are the interactions AI agents are best suited for - high volume, predictable patterns, resolvable from data.
Containment rates of 50-70% at 6 months, climbing to 60-80% by 12 months for teams that actively iterate. The variation depends heavily on integration depth - agents that can take action retain customers that agents which can only answer questions will lose to escalation.
Containment rates of 40-60% are typical when the AI agent is handling a broad interaction mix including cases that genuinely require human judgment. Attempting to automate everything at once typically produces a lower average containment rate than starting narrow and expanding - because the hard interactions drag down the metrics while the agent is still learning.
Vendors claiming 80-90% deflection rates across all interaction types in early deployment. At that level, either the interaction mix is unusually simple, the deflection definition includes abandonment, or the numbers are not being measured the way you think they are. Ask for re-contact rate and CSAT alongside any deflection claim.
If deflection rate is a misleading leading metric, what should you track instead? These four give a complete picture.
Contacts fully handled by the AI agent without escalation AND with a positive or neutral customer outcome signal. Measured by pairing containment rate with post-interaction CSAT or a resolution confirmation step at the end of the conversation. This is your primary performance metric.
The percentage of customers who contact support again within 24-48 hours of an AI-handled interaction. A high re-contact rate signals that the AI closed interactions without actually resolving them - customers are coming back because they still have the problem. This is the clearest signal that your deflection rate is inflated relative to your actual resolution quality.
When the AI agent does escalate to a human, how good is the handoff? Does the human agent have the context they need? How quickly do they resolve the escalated interaction? A low escalation quality score means the AI is not just failing to contain - it is making the human-handled interactions more expensive by providing poor context or escalating at the wrong moment.
The fully-loaded cost of resolving a support interaction, blended across AI-handled and human-handled contacts. This is the metric that connects AI performance to business outcomes most directly. As your successful containment rate rises and your human agents handle a more concentrated set of genuinely complex interactions, cost per resolution should fall. If it is not falling, something in the deployment is not working as expected.
The teams achieving the highest containment rates at 12 months are rarely the ones with the highest rates at 30 days. Early deployment containment is limited by knowledge gaps, integration scope, and the agent's initial calibration. Teams that invest in improving those things consistently see containment rates climb quarter over quarter.
The drivers of improvement are predictable:
The compounding effect is real. Teams that build these practices into their operational rhythm from the start consistently outperform teams that deploy and move on.
Deflection rate is often the number stakeholders ask about because it is the number vendors have trained them to ask about. If you are managing expectations internally for an AI support deployment, reframe the conversation early.
A useful framing: the goal is not to maximize how many tickets the AI handles. The goal is to maximize successful resolutions while reducing cost per resolution and maintaining customer satisfaction. Deflection rate is one signal in that picture, not the destination.
Set targets for successful containment rate at 90 days, 6 months, and 12 months - with the explicit expectation that 90-day numbers will be lower than 12-month numbers, and that improvement is a function of investment in iteration, not just time. Pair every deflection metric with a CSAT metric from the same interaction set. And track re-contact rate from day one - it is the earliest signal that your deflection numbers are telling the truth.
The right benchmarks for your deployment depend on your interaction mix, your current integration depth, and how your team is resourced to iterate. Voiceflow's team works with enterprise support leaders to scope realistic containment targets based on comparable customers - and to build agents designed for resolution, not just deflection.
Book a personalized demo with Voiceflow →
Bring your ticket taxonomy and your current metrics. We will show you what the numbers should look like.
.avif)
.avif)

